设计实时输入联想建议系统
我们来设计一个实时联想建议服务,该服务将在用户输入搜索文本时推荐相关术语。
类似服务:自动联想、实时输入搜索
难度:中等
1. 什么是实时输入联想建议?
实时输入联想建议帮助用户搜索常见和高频搜索术语。当用户在搜索框中输入字符时,系统会根据已输入的内容预测查询,并提供一组建议来补全查询。这种功能的目的是帮助用户更好地构建搜索查询,而不是单纯加快搜索速度。它通过引导用户并为其提供支持,帮助他们完善搜索内容。
2. 系统的需求和目标
功能性需求:
- 当用户输入查询时,系统应建议以用户输入内容开头的前10个术语。
非功能性需求:
- 建议结果应实时显示。
- 用户需要在200毫秒内看到建议列表。
3. 基本系统设计与算法
我们需要解决的问题是存储大量“字符串”,以便用户可以通过任意前缀进行搜索。我们的服务将根据给定的前缀建议匹配的下一个词。例如,如果数据库包含以下词条:cap、cat、captain、capital,当用户输入“cap”时,系统应建议“cap”、“captain”和“capital”。
由于需要处理大量查询且保证最低延迟,我们需要设计一种方案,高效地存储数据并快速查询。此需求无法依赖某种数据库,而是需要在内存中使用一种高效的数据结构存储索引。
一种非常适合我们需求的数据结构是Trie(发音为“try”)。Trie是一种类树形的数据结构,用于存储短语,其中每个节点按顺序存储短语的一个字符。例如,如果需要在Trie中存储“cap, cat, caption, captain, capital”,其结构将如下所示:
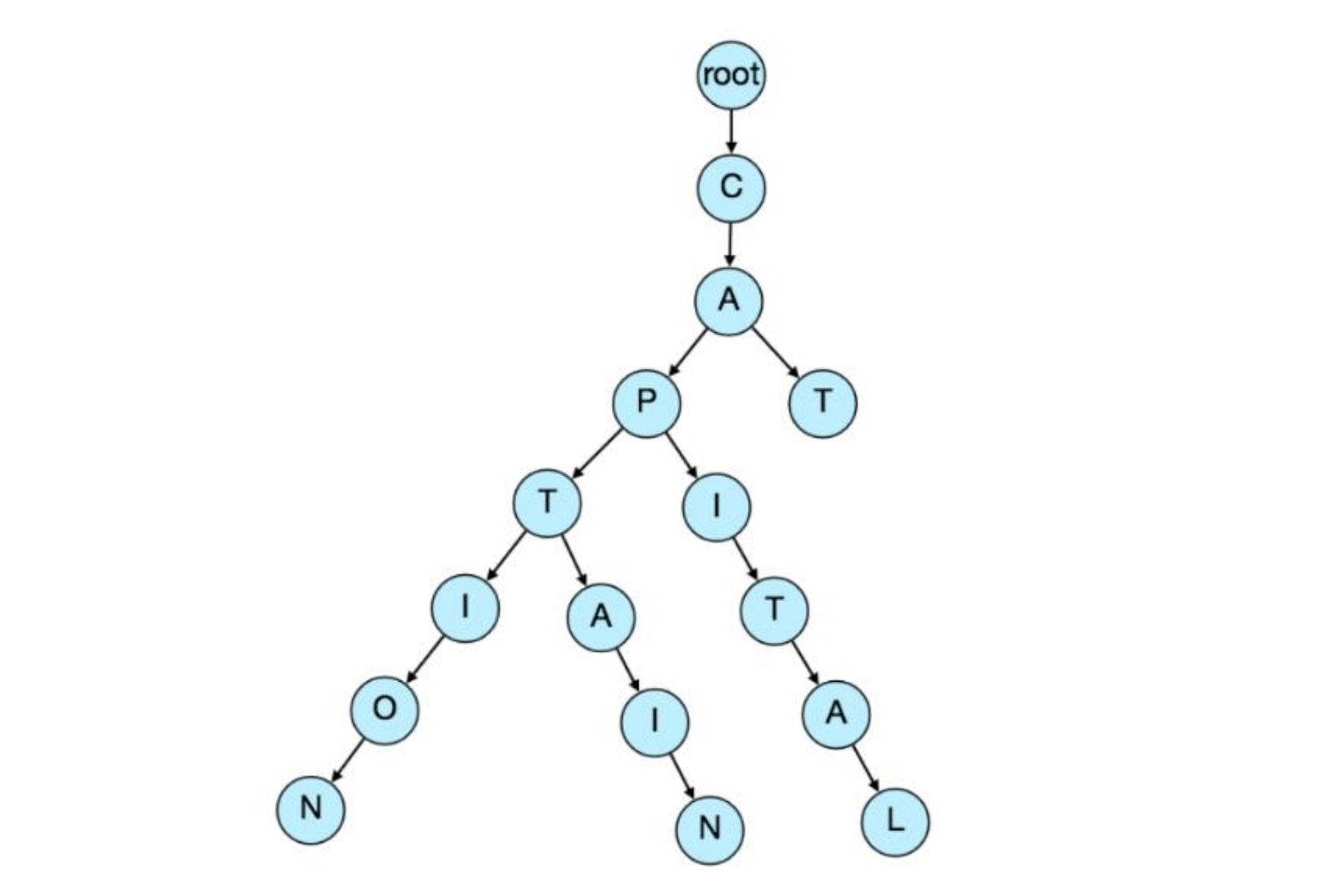
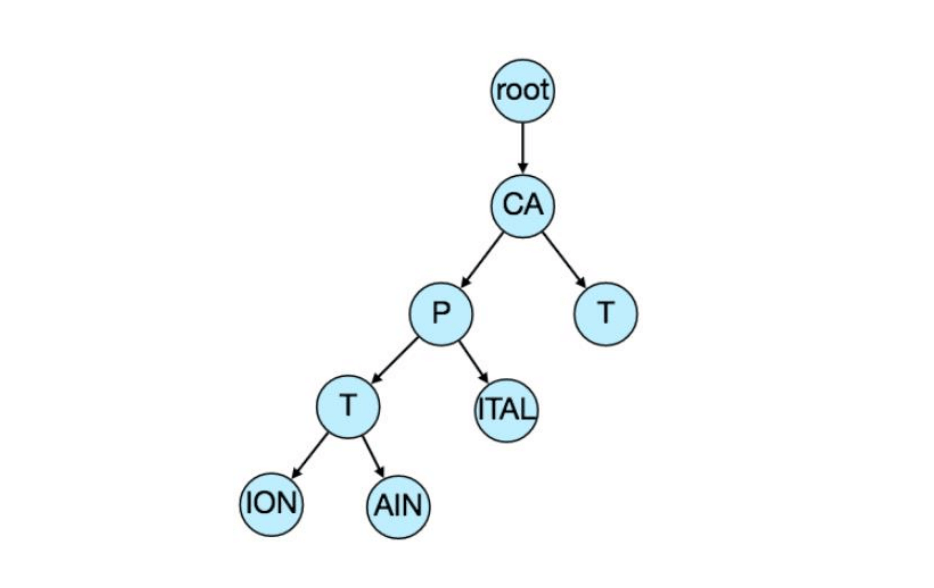
现在,如果用户输入了“cap”,我们的服务可以遍历Trie,找到节点‘P’,然后查找所有以该前缀开始的词条(例如:caption、capital等)。我们可以合并仅有一个分支的节点,以节省存储空间。上述Trie可以像这样存储:
我们是否应该使用不区分大小写的Trie? 为了简化和符合搜索用例,我们假设我们的数据是大小写不敏感的。
如何找到最佳建议? 现在我们可以根据前缀查找所有的词条,那么我们如何知道应该推荐哪些是前10个最常搜索的词条呢?一种简单的解决方案是存储在每个节点终止的搜索次数,例如,如果用户搜索“CAPTAIN”100次,“CAPTION”500次,我们可以将这个数字存储在短语的最后一个字符处。因此,当用户输入“CAP”时,我们知道在前缀“CAP”下最常搜索的词是“CAPTION”。因此,给定一个前缀,我们可以遍历其子树来查找最佳建议。
给定一个前缀,遍历其子树需要多少时间? 考虑到我们需要索引的数据量,我们应该预期树会非常庞大。即使是遍历一个子树也会非常耗时,例如短语“system design interview questions”有30层深。由于我们有非常严格的延迟要求,我们确实需要提高解决方案的效率。
我们能否在每个节点存储最优建议? 这肯定能加快搜索速度,但会需要大量的额外存储空间。我们可以在每个节点存储前10个建议,供我们返回给用户。为了实现所需的效率,我们必须承受存储容量的大幅增加。
我们可以通过仅存储终端节点的引用来优化存储,而不是存储整个短语。为了找到建议的词条,我们需要使用从终端节点的父节点引用回溯。我们还需要存储每个引用的频率,以跟踪最佳建议。
我们如何构建这个Trie? 我们可以高效地自底向上构建Trie。每个父节点将递归地调用所有子节点,计算它们的最佳建议和计数。父节点将从所有子节点合并最佳建议,以确定它们的最佳建议。
如何更新Trie? 假设每天有50亿次搜索,大约每秒60K个查询。如果我们尝试在每个查询时更新Trie,将非常耗费资源,且可能会影响读取请求。处理这个问题的一种解决方案是,在一定时间间隔后离线更新Trie。
随着新查询的到来,我们可以记录它们并跟踪它们的频率。我们可以记录每个查询,或者进行采样,只记录每1000个查询。例如,如果我们不希望显示搜索次数少于1000次的词条,那么记录每1000个查询的词条是安全的。
我们可以设置一个 Map-Reduce (MR)系统,定期处理所有日志数据,例如每小时一次。这些MR作业将计算过去一小时内所有搜索词的频率。然后,我们可以使用这些新数据更新我们的Trie。我们可以获取Trie的当前快照,并将所有新的词条及其频率更新进去。我们应该在离线进行此操作,以避免读查询被更新Trie的请求阻塞。我们可以有两种选择:
- 我们可以在每个服务器上复制Trie,并在离线更新它。完成后,我们可以切换到新Trie并丢弃旧的Trie。
- 另一种选择是为每个Trie服务器设置主从配置。在主服务器处理流量时,我们可以更新从服务器。更新完成后,我们可以将从服务器切换为新的主服务器。之后,我们可以更新旧的主服务器,使其也开始处理流量。
如何更新联想建议的频率? 由于我们在每个节点上存储联想建议的频率,我们也需要更新这些频率。我们可以仅更新频率的差异,而不是重新计算所有搜索词。如果我们记录过去10天内搜索的所有词条的计数,我们需要减去不再包含的时间段的计数,并添加新时间段的计数。我们可以基于每个词条的指数移动平均(EMA)来加减频率。在EMA中,我们对最新数据赋予更大的权重,也叫做指数加权移动平均。
在向Trie中插入新词条后,我们将进入该短语的终端节点并增加其频率。由于我们在每个节点存储前10个查询词条,这个特定的搜索词可能会跳入其他几个节点的前10个查询中。因此,我们需要更新这些节点的前10个查询。我们必须从该节点回溯,直到根节点。对于每个父节点,我们检查当前查询是否是前10个中的一部分。如果是,我们更新相应的频率。如果不是,我们检查当前查询的频率是否足够高,能够成为前10个中的一部分。如果是,我们插入这个新词条,并移除频率最低的词条。
如何从Trie中移除一个词条? 假设由于某些法律问题、仇恨言论或盗版等原因,我们需要从Trie中移除一个词条。我们可以在常规更新时完全移除这些词条,同时,在每个服务器上可以添加一个过滤层,在将数据发送给用户之前移除这些词条。
建议的排名标准可能有哪些不同的标准? 除了简单的计数外,我们在对词条进行排名时,还需要考虑其他因素,例如新鲜度、用户位置、语言、人口统计、个人历史等。
4. Trie的持久化存储
如何将Trie存储到文件中,以便我们可以轻松地重建它——这在机器重启时是必要的?我们可以定期对Trie进行快照并将其存储到文件中,这样当服务器宕机时就能重建Trie。存储时,可以从根节点开始,按层级逐层保存Trie。对于每个节点,我们可以存储它包含的字符以及它有多少子节点。在每个节点之后,紧接着存储它的所有子节点。例如,假设我们有以下Trie:
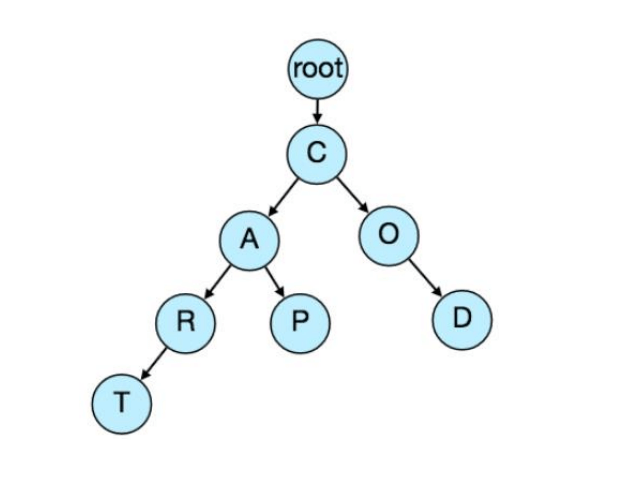
如果我们按照上述方案将该Trie存储到文件中,结果会是:"C2,A2,R1,T,P,O1,D"。通过这个数据,我们可以轻松地重建Trie。
如果你注意到,我们并没有在每个节点中存储最佳建议及其计数。存储这类信息非常困难,因为Trie是自上而下存储的,在父节点创建之前,子节点尚未生成,因此无法轻松存储它们的引用。为了解决这个问题,我们需要在构建Trie的过程中重新计算所有最佳词条及其计数。
具体而言,每个节点在构建时会计算自己的最佳建议并将其传递给父节点。父节点会合并所有子节点的结果,从而确定自己的最佳建议。
5. 规模估算
如果我们构建的服务规模与Google相当,每天可以预期有50亿次搜索,这大约相当于每秒60,000次查询。
由于50亿次查询中会有大量重复项,我们可以假设只有20%的查询是唯一的。如果我们只想索引最热门的50%搜索词条,可以排除很多低频搜索的查询。假设我们需要为1亿个唯一词条构建索引。
存储估算: 如果每个查询平均由3个单词组成,并且每个单词的平均长度为5个字符,则平均查询大小为15个字符。假设存储一个字符需要2字节,那么存储一个查询需要30字节。总存储需求为:
1亿个词条 × 30字节 = 3 GB
考虑到数据量每天可能会增长,同时也会删除一些不再被搜索的词条。如果假设每天有2%的新增查询,并且我们维护过去一年的索引,预计的总存储需求为:
3 GB + (0.02 × 3 GB × 365 天) = 25 GB
6. 数据分区
尽管我们的索引可以轻松地适配到单个服务器上,但为了实现更高的效率和更低的延迟,仍可以对其进行分区。如何有效地对数据进行分区以将其分布到多个服务器上?
a. 基于范围的分区
假设我们根据短语的首字母将其存储在不同的分区中,例如,将所有以字母“A”开头的术语存储在一个分区中,以“B”开头的存储在另一个分区中,以此类推。对于出现频率较低的字母,还可以将它们合并到一个数据库分区中。
这种分区方案需要在静态情况下设计,以确保数据的存储和查询始终具有可预测性。
此方法的主要问题是可能导致服务器负载不平衡。例如,如果我们将所有以字母“E”开头的术语存储在一个分区中,但后来发现“E”开头的术语数量过多,以至于无法容纳在一个数据库分区中。
上述问题几乎会出现在所有静态定义的分区方案中,因为无法在静态情况下预测每个分区是否能够适配到单个服务器。
b. 基于服务器最大容量的分区
假设我们根据服务器的最大内存容量对trie结构进行分区。只要服务器内存充足,我们可以将数据存储在该服务器中。当某个子树无法适配当前服务器时,就在此处断开分区,将范围分配给当前服务器,然后转到下一个服务器继续这个过程。例如:
- 第一台服务器存储从“A”到“AABC”的所有术语;
- 第二台服务器存储从“AABD”到“BXA”的术语;
- 第三台服务器存储从“BXB”到“CDA”的术语。
我们可以通过哈希表快速访问这一分区方案:
- 服务器1:A-AABC
- 服务器2:AABD-BXA
- 服务器3:BXB-CDA
查询场景:
- 如果用户输入“A”,需要同时查询服务器1和服务器2以找到推荐结果;
- 如果用户输入“AA”,仍需查询服务器1和服务器2;
- 当用户输入“AAA”时,只需查询服务器1即可。
可以在trie服务器前设置一个负载均衡器,存储分区映射并将流量重定向到相应的服务器。如果需要从多个服务器查询数据,可以选择在服务器端合并结果,或者让客户端处理合并。如果在服务器端处理合并,则需要在负载均衡器和trie服务器之间添加一个聚合层(称为“聚合服务器”),这些服务器负责从多个trie服务器中聚合结果并返回给客户端。
缺点:即使基于最大容量分区,仍可能导致热点问题,例如,对于大量以“cap”开头的查询,请求集中到某一台服务器时会造成高负载。
c. 基于术语哈希的分区
将每个术语传递给一个哈希函数,由该函数生成服务器编号,然后将术语存储在对应的服务器上。这种方法会使术语分布随机化,从而最大限度地减少热点问题。
查询过程:为获取某个术语的联想推荐,需要访问所有服务器并聚合结果。
7. 缓存
我们应该意识到,对最常搜索的词进行缓存对我们的服务将非常有帮助。会有一小部分查询占据大多数的流量。我们可以在前端部署独立的缓存服务器,缓存最常搜索的词及其自动补全建议。
应用服务器在访问trie服务器之前,应先检查这些缓存服务器,查看是否已包含所需的搜索词。
我们还可以构建一个简单的机器学习(ML)模型,根据简单的计数、个性化推荐或趋势数据等,预测每个建议的参与度,并缓存这些词汇。
8. 复制与负载均衡
我们应为trie服务器设置副本,以实现负载均衡和容错。此外,还需要一个负载均衡器来跟踪数据分区方案,并根据前缀将流量重定向。
9. 容错机制
当trie服务器宕机时会发生什么?如上所述,我们可以采用主从配置;如果主服务器故障,从服务器可在故障切换后接管。任何重新上线的服务器都可以根据最新快照重建trie。
10. 输入提示客户端优化
我们可以在客户端进行以下优化,以提升用户体验:
- 只有在用户停止按键50毫秒后,客户端才应尝试与服务器交互。
- 如果用户持续输入,客户端可取消正在进行的请求。
- 初始阶段,客户端可等待用户输入几个字符后再发送请求。
- 客户端可以预先从服务器获取部分数据,以减少未来的请求次数。
- 客户端可以本地存储最近的建议记录,因为这些记录的复用率极高。
- 提前与服务器建立连接是关键因素之一。当用户打开搜索引擎网站时,客户端应立即与服务器建立连接,从而在用户输入第一个字符时无需浪费时间建立连接。
- 服务器可将部分缓存推送至内容分发网络(CDN)和互联网服务提供商(ISP)以提高效率。
11. 个性化
用户会根据其历史搜索、位置、语言等因素获得个性化输入提示。我们可以在服务器上单独存储每位用户的个人历史,并在客户端缓存这些数据。服务器在向用户发送最终结果前,可将这些个性化术语添加到结果集中。个性化搜索结果应始终优先于其他结果。