设计一个网页爬虫
让我们设计一个能够系统地浏览和下载全球互联网的网页爬虫。网页爬虫也被称为网页蜘蛛、机器人、蠕虫、行走者和机器人程序。
难度级别:难
1. 什么是网页爬虫?
网页爬虫是一种以系统化和自动化方式浏览万维网的软件程序。它通过递归地从一组起始页面抓取链接来收集文档。许多网站,特别是搜索引擎,使用网页爬虫来提供最新数据。搜索引擎会下载所有页面并对其创建索引,以实现更快速的搜索。
网页爬虫的一些其他用途包括:
- 测试网页和链接的语法及结构是否有效。
- 监控网站的结构或内容变化。
- 为流行网站维护镜像站点。
- 搜索版权侵权内容。
- 构建专用索引,例如对存储在多媒体文件中的内容进行理解的索引。
2. 系统需求和目标
假设我们需要抓取整个万维网。
- 可扩展性:我们的服务需要具备可扩展性,能够抓取整个万维网,并用于获取数亿个网页文档。
- 可扩展性:我们的服务应设计为模块化结构,以便在未来增加新功能。例如,可能需要下载和处理新的文档类型。
3. 一些设计考量
抓取万维网是一个复杂的任务,有多种实现方式。在进一步设计之前,我们需要提出以下问题:
爬虫是否仅针对 HTML 页面?还是需要抓取和存储其他类型的媒体(如音频文件、图像、视频等)?
这是一个重要问题,因为答案会影响设计。如果我们要构建一个通用爬虫,用于下载不同类型的媒体文件,可能需要将解析模块拆分为不同的子模块:一个用于 HTML,另一个用于图像,还有一个用于视频,每个模块提取对应媒体类型中有意义的内容。
目前假设我们的爬虫只处理 HTML,但应确保其可扩展性,以便未来能够轻松支持新媒体类型。爬虫将处理哪些协议?仅 HTTP?是否包括 FTP 链接?
我们的爬虫应支持哪些协议?为了当前的练习,假设只处理 HTTP。但设计应具有可扩展性,以便未来可以支持 FTP 和其他协议。预期爬取的页面数量是多少?URL 数据库的规模有多大?
假设我们需要爬取 10 亿个网站。由于每个网站可能包含许多 URL,我们可以假设爬虫需要访问的网页数量上限为 150 亿。什么是 RobotsExclusion?我们该如何处理?
礼貌的网页爬虫需要实现机器人排除协议(Robots Exclusion Protocol)。该协议允许网站管理员声明网站某些部分禁止爬虫访问。
机器人排除协议要求爬虫在抓取实际内容之前,先获取并解析网站的robots.txt文件,该文件包含相关声明。
4. 容量估算和约束
如果我们希望在四周内抓取 150 亿个页面,需要每秒抓取的页面数量为:
15B / (4 weeks * 7 days * 86400 sec) ~= 6200 pages/sec存储需求:
页面大小差异较大,但由于我们仅处理 HTML 文本,假设每个页面的平均大小为 100KB。如果每个页面还存储 500 字节的元数据,则总存储需求为:
15B * (100KB + 500) ~= 1.5 petabytes总存储容量:
假设存储系统的容量使用率不超过 70%(70% 容量模型),总存储需求为:
1.5 petabytes / 0.7 ~= 2.14 petabytes5. 高层设计
网页爬虫的基本算法是以一组种子 URL 作为输入,反复执行以下步骤:
- 从未访问的 URL 列表中选择一个 URL。
- 确定其主机名的 IP 地址。
- 建立与主机的连接以下载对应的文档。
- 解析文档内容以寻找新的 URL。
- 将新发现的 URL 添加到未访问的 URL 列表中。
- 处理下载的文档,例如存储或索引其内容等。
- 返回步骤 1。
如何抓取?
广度优先或深度优先?
通常使用广度优先搜索(BFS)。
但在某些情况下,也会使用深度优先搜索(DFS),例如,当爬虫已经与某个网站建立连接时,可能会通过 DFS 抓取该网站的所有 URL,以节省握手开销。路径递增抓取:
路径递增抓取有助于发现许多孤立资源,或在常规爬取中找不到的资源。
在这种方法中,爬虫会尝试逐层向上抓取每个 URL 的路径。例如,当给定种子 URL 为http://foo.com/a/b/page.html时,爬虫将尝试抓取/a/b/、/a/和/。
实现高效爬虫的难点
海量网页:
由于网页数量巨大,爬虫在任意时刻只能下载其中的一部分。因此,爬虫需要具备足够的智能来优先下载重要的页面。网页的变化率:
在当今动态的网络环境中,网页变化非常频繁。爬虫可能在下载某网站的最后一个页面时,该页面已经更新,或者网站中新增了页面。
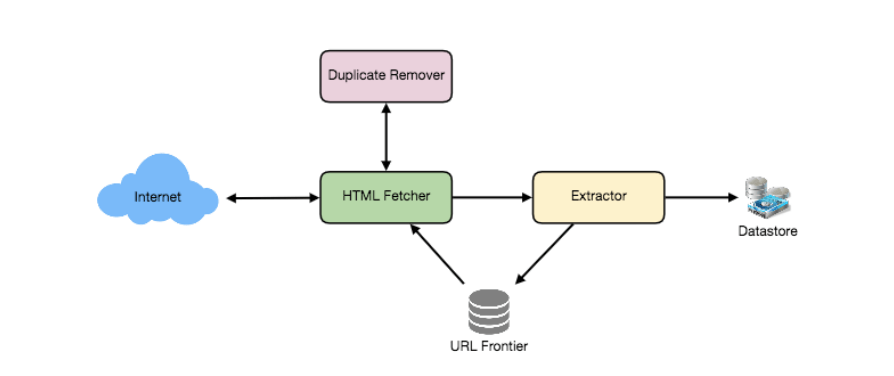
爬虫的最低组件需求
URL 列表(URL Frontier):
用于存储需要下载的 URL 列表,并对 URL 的爬取顺序进行优先级排序。HTTP 抓取器(HTTP Fetcher):
用于从服务器检索网页。解析器(Extractor):
用于从 HTML 文档中提取链接。重复消除器(Duplicate Eliminator):
确保不会无意中重复抓取相同的内容。数据存储(Datastore):
用于存储已抓取的页面、URL 和其他元数据。
6. 详细组件设计
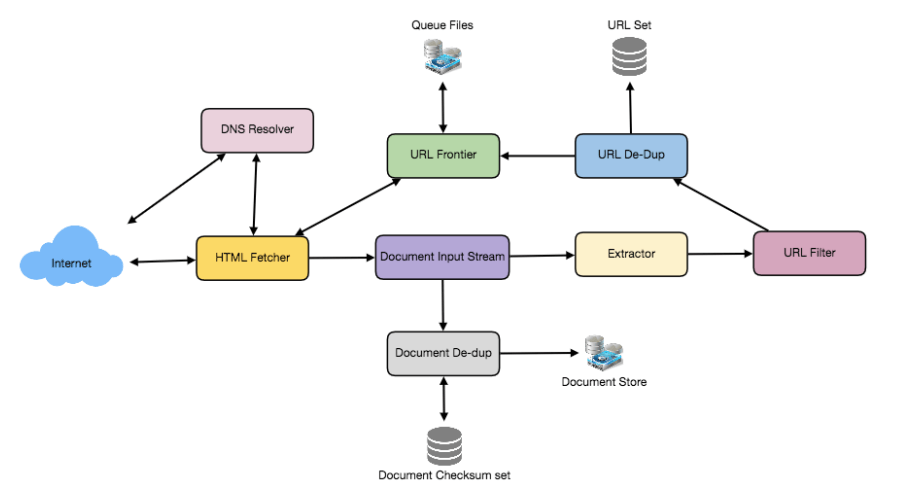
假设爬虫运行在一台服务器上,所有爬取任务由多个工作线程完成,每个线程在循环中执行下载和处理文档的所有步骤。
循环的第一步是从共享的 URL 列表(URL Frontier)中移除一个绝对 URL 以进行下载。绝对 URL 以协议开头(例如“HTTP”),用于标识下载所需的网络协议。我们可以以模块化方式实现这些协议,从而在将来需要支持更多协议时能够轻松扩展。根据 URL 的协议,工作线程调用相应的协议模块来下载文档。文档下载后会被放入文档输入流(Document Input Stream,DIS)。将文档放入 DIS 可以让其他模块多次读取该文档。
文档写入 DIS 后,工作线程调用去重测试(Dedupe Test),以判断该文档(关联不同的 URL)是否已被处理过。如果文档已存在,则不再进一步处理,工作线程继续从 URL 列表中移除下一个 URL。
接下来,爬虫需要处理下载的文档。每个文档可能具有不同的 MIME 类型,例如 HTML 页面、图像、视频等。我们可以以模块化方式实现这些 MIME 类型的处理模块,从而在将来需要支持更多类型时能够轻松扩展。根据文档的 MIME 类型,工作线程调用与该 MIME 类型相关联的处理模块的 process 方法。
此外,HTML 处理模块会从页面中提取所有链接。每个链接都会被转换为绝对 URL,并根据用户提供的 URL 过滤器进行测试,以确定是否需要下载。如果 URL 通过过滤器测试,工作线程会进行 URL 已见测试(URL-Seen Test),检查该 URL 是否已被访问(即是否已在 URL 列表中或已被下载)。如果 URL 是新的,则将其添加到 URL 列表中。
让我们逐一讨论这些组件,并分析它们如何分布到多台机器上:
- URL 队列 (URL Frontier):
URL 队列是一个数据结构,包含所有尚未下载的 URL。我们可以通过对网页进行广度优先遍历(从种子集合中的页面开始)来进行爬取。此类遍历可以通过使用 FIFO 队列轻松实现。
由于我们需要爬取大量的 URL,可以将 URL 队列分布到多个服务器上。假设每台服务器上有多个工作线程负责执行爬取任务,同时假设我们的哈希函数会将每个 URL 映射到一个负责爬取它的服务器。
在设计分布式 URL 队列时,必须遵循以下友好性约束:
- 爬虫不能通过下载大量页面使目标服务器超载。
- 不应让多台机器同时连接同一个 Web 服务器。
为实现这些友好性约束,可以在每台服务器上维护一组独立的 FIFO 子队列。每个工作线程将拥有一个独立的子队列,从中取出 URL 进行爬取。当需要添加新 URL 时,其放入的 FIFO 子队列将由 URL 的规范化主机名决定。哈希函数可以将每个主机名映射到一个线程编号。
综合这两点,最多只有一个工作线程会从给定的 Web 服务器下载文档,并且通过使用 FIFO 队列,爬虫不会使目标服务器超载。
我们的 URL 队列将有多大? 其大小将达到数亿个 URL。因此,我们需要将 URL 存储在磁盘上。我们可以通过实现一种队列方式,使其具有独立的入队和出队缓冲区。当入队缓冲区填满时,它将被写入磁盘,而出队缓冲区则保持需要访问的 URL 缓存,它可以定期从磁盘读取以填充缓冲区。
抓取模块 (Fetcher Module):
抓取模块的目的是使用适当的网络协议(如 HTTP)下载与给定 URL 对应的文档。如前所述,站点管理员会创建robots.txt文件,以使某些网站部分对爬虫不可访问。为了避免每次请求都下载此文件,我们的爬虫 HTTP 协议模块可以维护一个固定大小的缓存,将主机名映射到其robots.txt的排除规则。文档输入流 (Document Input Stream, DIS):
我们的爬虫设计使得同一文档可以被多个处理模块处理。为了避免多次下载文档,我们使用一种名为文档输入流(DIS)的抽象来本地缓存文档。
DIS 是一个输入流,缓存从互联网上读取的文档的完整内容,并提供重新读取文档的方法。对于小型文档(64KB 或更小),DIS 可以将其完整缓存到内存中,而较大的文档则可以临时写入一个后备文件。
每个工作线程都有一个关联的 DIS,并在文档之间重复使用它。工作线程从队列中提取 URL 后,将该 URL 传递给相关协议模块,该模块通过网络连接初始化 DIS 来加载文档内容。然后,工作线程将 DIS 传递给所有相关的处理模块。文档去重测试 (Document Dedupe Test):
许多 Web 文档可以通过多个不同的 URL 获取,还有许多文档在不同的服务器上有镜像。这些现象会导致爬虫多次下载相同的文档。为了防止文档被重复处理,我们对每个文档执行去重测试,以去除重复。
为了执行此测试,我们可以计算每个处理文档的 64 位校验和,并将其存储在数据库中。对于每个新文档,我们可以将其校验和与所有已计算的校验和进行比较,以查看该文档是否已经出现过。我们可以使用 MD5 或 SHA 来计算这些校验和。那么,校验和存储会有多大呢?如果我们校验和存储的唯一目的是去重,那么我们只需要保留一个包含所有已处理文档校验和的唯一集合。假设我们有 150 亿个独特的网页,我们需要:
150 亿 × 8 字节 = 120 GB尽管这一数据可以存储在现代服务器的内存中,如果内存不足,我们可以在每台服务器上使用较小的基于 LRU 的缓存,并将所有数据存储在持久存储中。去重测试首先检查校验和是否存在于缓存中。如果没有,它将检查校验和是否存在于后备存储中。如果找到该校验和,文档将被忽略。否则,校验和将被添加到缓存和后备存储中。
URL 过滤器 (URL Filters):
URL 过滤机制提供了一种可定制的方式来控制下载的 URL 集合。它用于将网站列入黑名单,以使我们的爬虫忽略它们。在将每个 URL 添加到队列之前,工作线程会查阅用户提供的 URL 过滤器。我们可以定义过滤器,通过域名、前缀或协议类型来限制 URL。域名解析 (Domain Name Resolution):
在与 Web 服务器建立联系之前,Web 爬虫必须使用域名服务 (DNS) 将 Web 服务器的主机名映射到 IP 地址。鉴于我们将处理的 URL 数量,DNS 名称解析将成为爬虫的一个瓶颈。为了避免重复请求,我们可以通过建立本地 DNS 服务器来开始缓存 DNS 结果。URL 去重测试 (URL Dedupe Test):
在提取链接时,任何 Web 爬虫都会遇到指向同一文档的多个链接。为了避免重复下载和处理文档,必须在将每个提取的链接添加到 URL 队列之前,执行 URL 去重测试。
为了执行 URL 去重测试,我们可以将爬虫遇到的所有 URL 以规范形式存储在数据库中。为了节省空间,我们不在 URL 集合中存储每个 URL 的文本表示,而是存储一个固定大小的校验和。
为了减少数据库存储上的操作,我们可以在每台主机上为所有线程共享一个热门 URL 的内存缓存。之所以使用缓存,是因为某些 URL 的链接非常常见,将这些热门 URL 缓存在内存中可以提高内存命中率。那么我们需要多大的存储空间来存储 URL?如果我们校验和的唯一目的是进行 URL 去重,那么我们只需保留一个唯一集合,包含所有已见过的 URL 的校验和。假设有 150 亿个独特的 URL,且校验和大小为 4 字节,我们需要:
150 亿 × 4 字节 = 60 GB我们能使用布隆过滤器进行去重吗?布隆过滤器是一种用于集合成员测试的概率性数据结构,可能会产生假阳性。一个大型位向量表示该集合。通过计算元素的
n个哈希函数并设置相应的位来将元素添加到集合中。如果元素的所有n个哈希位置的位都被设置,则认为该元素在集合中。因此,某个文档可能被错误地认为在集合中,但不会出现假阴性。
使用布隆过滤器进行 URL 去重测试的缺点是,每次假阳性都会导致该 URL 无法添加到队列,从而该文档永远不会被下载。通过增大位向量的大小,可以减少假阳性的概率。检查点 (Checkpointing):
完成整个 Web 的爬取需要几周时间。为了防止爬取过程中出现故障,我们的爬虫可以定期将其状态快照写入磁盘。被中断或终止的爬取可以从最新的检查点轻松恢复。
7. 容错性 (Fault Tolerance):
我们应该使用一致性哈希(Consistent Hashing)来实现爬虫服务器之间的任务分配。
一致性哈希不仅可以在主机宕机时替换掉失效主机,还可以帮助在爬虫服务器之间分配负载。
所有爬虫服务器都会定期进行检查点操作,将其 FIFO 队列存储到磁盘中。如果某台服务器宕机,我们可以替换它。同时,一致性哈希会将负载转移到其他服务器上。
8. 数据分区 (Data Partitioning):
我们的爬虫将处理以下三类数据:
- 待访问的 URL;
- 用于去重的 URL 校验和;
- 用于去重的文档校验和。
由于我们基于主机名分配 URL,因此可以将这些数据存储在同一主机上。每台主机将存储以下内容:
- 其需要访问的一组 URL;
- 所有已访问 URL 的校验和;
- 所有已下载文档的校验和。
由于使用了一致性哈希,URL 可以从超载的主机重新分配到其他主机。
每台主机会定期执行检查点操作,将其所有数据的快照转储到远程服务器。这确保了如果某台服务器宕机,其他服务器可以通过从最新的快照中恢复数据来替换它。
9. 爬虫陷阱 (Crawler Traps):
爬虫会遇到许多陷阱,包括垃圾网站和伪装内容。爬虫陷阱是指某些 URL 或一组 URL 会导致爬虫无限制地爬取。例如:
- 非故意的陷阱:文件系统中的符号链接可能会创建一个循环,从而让爬虫进入死循环。
- 故意设置的陷阱:某些人故意设置陷阱,动态生成无限量的网页文档。
设置这些陷阱的动机各不相同。例如:
- 反垃圾邮件陷阱:专门针对用于抓取电子邮件地址的垃圾邮件爬虫;
- 搜索引擎干扰陷阱:试图引诱搜索引擎爬虫,提升其搜索排名。