设计 Uber 后端
我们来设计一个类似 Uber 的网约车服务,它连接需要乘车的乘客和提供车辆的司机。
类似服务:Lyft、滴滴、Via、Sidecar 等
难度等级:困难
前置知识:设计 Yelp
1. 什么是 Uber?
Uber 允许用户预订司机进行出租车服务。Uber 司机使用自己的私家车载客,乘客和司机通过智能手机上的 Uber 应用程序进行沟通。
2. 系统的需求和目标
我们先构建一个简化版的 Uber。
系统中有两类用户:
- 司机
- 乘客
- 司机需要定期向系统报告自己的当前位置及是否可接单。
- 乘客可以看到附近所有可用的司机。
- 乘客可以发起打车请求,附近的司机会收到通知,提示有乘客等待接载。
- 一旦司机和乘客确认行程,他们可以实时查看彼此的位置,直到行程结束。
- 到达目的地后,司机标记行程完成,进入可接单状态。
3. 规模估算与约束
- 假设系统有 3 亿乘客 和 100 万司机,其中 每日活跃用户(DAU) 为 100 万乘客 和 50 万司机。
- 每日约有 100 万次行程。
- 所有活跃司机每 3 秒 上报一次当前位置。
- 乘客发起行程请求后,系统需要实时联系附近的司机。
4. 基础系统设计与算法
我们将基于 《设计 Yelp》 中讨论的方案,并对其进行修改,使其适用于上述 Uber 相关的使用场景。
最大的问题在于,我们之前的 四叉树(QuadTree) 设计时,并未考虑到频繁更新的问题。因此,我们的 动态网格(Dynamic Grid) 方案存在两个主要挑战:
高频位置更新的处理
- 所有活跃司机每 3 秒 上报一次位置,因此数据结构必须能够高效更新。
- 如果每次司机位置变化都要更新 四叉树,则计算和资源消耗都会很大。
- 具体而言,更新司机位置时,需要基于其之前的位置找到对应的网格。如果新位置不属于当前网格,就必须将司机从当前网格移除,并重新插入到正确的网格。
- 如果新网格的司机数量超过上限,还需要对其进行重新分区(repartition),进一步增加计算开销。
快速传播附近司机的位置信息
- 需要一种高效机制,能够实时将附近司机的位置信息传递给该区域内的所有活跃乘客。
- 当行程进行中,系统必须持续通知司机和乘客关于车辆的实时位置。
虽然 四叉树(QuadTree) 在查找附近司机时表现优秀,但它无法保证高效的更新,因此需要额外优化。
我们需要在每次司机上报位置时更新四叉树吗?
如果我们不在每次更新时修改四叉树,则四叉树中的部分数据会变旧,无法准确反映司机的当前位置。回顾之前的设计,我们构建 四叉树(QuadTree) 的目的是高效查找附近的司机。但由于所有活跃司机每 3 秒上报一次位置,导致更新操作的频率远高于查询操作。
优化方案:使用哈希表存储司机最新位置
- 我们可以将所有司机的最新位置存储在哈希表中,并降低四叉树的更新频率。
- 例如,我们可以保证司机的位置在 15 秒内反映到四叉树,而最新的位置信息存储在一个哈希表(称为 DriverLocationHT)。
DriverLocationHT 需要多少内存?
DriverLocationHT 需要存储 DriverID 以及司机的当前和上一位置,每条记录共 35 字节:
| 字段 | 大小 |
|---|---|
| DriverID | 3 字节(1 百万司机) |
| 旧纬度 | 8 字节 |
| 旧经度 | 8 字节 |
| 新纬度 | 8 字节 |
| 新经度 | 8 字节 |
| 合计 | 35 字节 |
假设系统有 100 万名司机,则所需内存(忽略哈希表开销):
1,000,000 × 35B = 35MB
接收位置更新所需的带宽
- 每次接收位置更新需要 19 字节(DriverID 3B + 位置 16B)。
- 100 万司机每 3 秒 上报一次:
1 million * 35 bytes => 35 MB即每 3 秒 19MB 的数据流量。
是否需要将 DriverLocationHT 分布式存储?
尽管 35MB 的内存占用和 19MB/3s 的带宽需求并不高,可以存储在单台服务器上,但出于可扩展性(scalability)、性能(performance)和容错性(fault tolerance)的考虑,我们应当分布式存储 DriverLocationHT。
分片策略:
- 可以基于 DriverID 进行分片,使数据均匀分布。
- 负责存储司机位置的服务器称为 Driver Location Server。
Driver Location Server 负责两项任务:
- 广播司机位置给所有关注该司机的乘客。
- 通知相应的四叉树服务器(QuadTree Server)刷新司机位置,该操作每 10 秒进行一次。
如何高效地将司机位置广播给乘客?
采用推送(Push)模型:
- 服务器将司机位置实时推送给所有相关用户。
- 通过 通知服务(Notification Service) 进行广播,该服务基于 发布/订阅(Pub/Sub)模型 构建。
实现方式:
- 当乘客打开 Uber APP 查询附近司机时,服务器返回司机列表,并订阅这些司机的位置更新。
- 服务器维护一个订阅列表,存储所有希望接收某司机位置更新的乘客。
- 当 DriverLocationHT 中司机的位置更新时,系统会向所有订阅的乘客推送最新位置。
这样可以确保乘客始终看到司机的最新位置。
存储所有订阅信息需要多少内存?
根据前面的估算,我们有 100 万日活乘客 和 50 万日活司机。假设每个司机平均有 5 个乘客订阅,并将订阅信息存储在哈希表中(以便高效更新)。
- DriverID: 3 字节
- CustomerID: 8 字节
所需总内存计算如下:
(500K * 3) + (500K * 5 * 8 ) ~= 21 MB广播司机位置所需的带宽
- 总订阅数:
5 * 500K => 2.5M- 每次更新需要传输的数据(DriverID 3B + 位置 16B = 19B)。
- 每秒更新频率:
2.5M * 19 bytes => 47.5 MB/s如何高效实现通知服务?
可以采用以下两种方案:
HTTP 长轮询(Long Polling)
- 客户端定期向服务器请求更新,并在服务器有新数据时返回。
- 缺点:会有额外的请求开销,增加服务器负载。
推送通知(Push Notifications)
- 服务器主动推送司机位置更新给所有订阅的乘客。
- 需要高效的 发布/订阅(Pub/Sub) 机制。
新进入的司机如何被现有乘客订阅?
当前订阅逻辑:
- 乘客打开 Uber APP 时,系统会订阅附近司机的位置更新。
- 但是,如果有新司机进入乘客所在区域,系统如何处理?
方案 1:动态添加订阅
- 需要跟踪乘客正在查看的区域,当有新司机进入该区域时,服务器自动订阅该司机。
- 缺点:逻辑复杂,需要持续维护区域状态。
方案 2:客户端主动查询(Pull Model)
- 乘客定期发送当前位置,服务器返回附近司机列表。
- 乘客收到更新后,更新界面以反映最新司机位置。
- 查询间隔:每 5 秒 查询一次,减少服务器压力。
- 优点:相比推送模式,实现更简单,减少服务器的持续推送负担。
是否需要立即重新划分超载的网格?
如果网格超出最大容量,是否立即分割?
- 优化方案:允许网格增长/收缩 10% 后再进行拆分/合并。
- 优势:
- 减少高流量区域的网格分裂频率,降低服务器计算负担。
- 提升性能,避免过于频繁的分区操作。
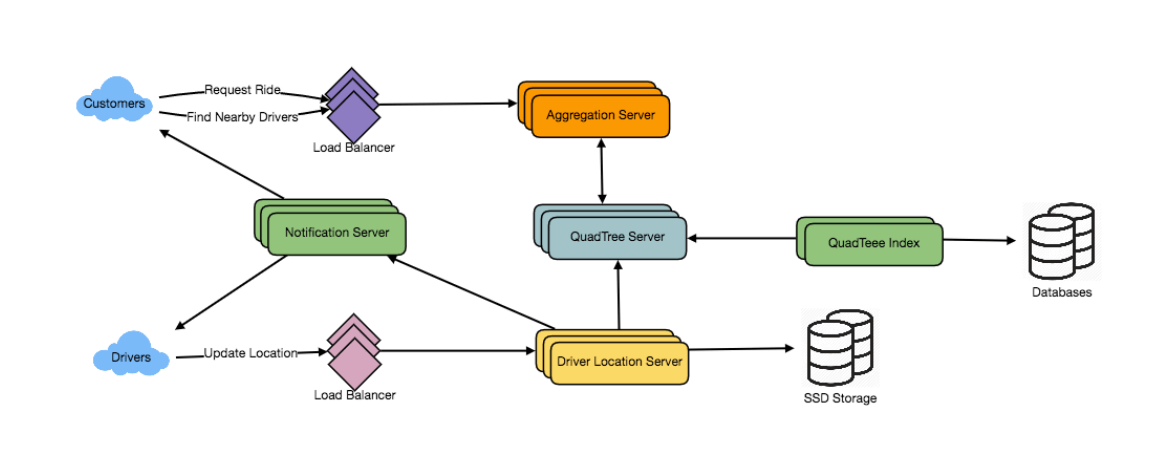
“请求乘车”用例如何运作?
- 乘客发起乘车请求。
- 其中一个聚合服务器(Aggregator server)接收该请求,并向四叉树(QuadTree)服务器请求附近的司机信息。
- 聚合服务器收集所有结果,并按照司机评分进行排序。
- 聚合服务器会同时向评分最高的前三名司机发送通知,最先接受请求的司机将被指派该订单,其余司机会收到取消请求。如果这三名司机都未响应,聚合服务器会继续向排序靠后的三名司机发起请求。
- 一旦有司机接受请求,乘客将收到通知。
5. 容错性与数据复制
如果 司机位置服务器 或 通知服务器 宕机,我们需要这些服务器的副本,以便在主服务器故障时,备用服务器可以接管。此外,我们可以将数据存储在 SSD 等高性能持久化存储中,以提供快速 I/O。这可以确保即使主服务器和备用服务器同时宕机,我们仍然可以从持久化存储中恢复数据。
6. 排序机制
如果我们不仅想按距离排序搜索结果,还想按受欢迎程度或相关性排序,该如何处理?
我们可以在数据库和四叉树(QuadTree)中维护每位司机的整体评分,例如,司机的评分可以用 10 分制的星级表示。在搜索给定半径内的前 10 名司机时,我们可以让 四叉树的每个分区 返回其评分最高的 10 名司机。然后,聚合服务器 从所有分区返回的结果中,最终选出评分最高的 10 名司机。
7. 高级问题
- 如何处理 网络较慢或不稳定 的客户端?
- 如果客户端在行程中 断开连接,如何处理 计费?
- 如果客户端主动拉取信息,而不是服务器主动推送,系统该如何设计?