索引
在数据库领域,索引是众所周知的。迟早会遇到数据库性能不再令人满意的情况,而数据库索引往往是应对这一问题的首选方案之一。
在数据库的特定表上创建索引的目的是加快搜索速度,以便更快地找到所需的行。索引可以基于数据库表中的一个或多个列创建,从而实现快速的随机查找以及高效的有序访问。
示例:图书馆目录
图书馆目录是一本包含馆藏书籍清单的登记簿。通常,它的结构类似于数据库表,包含四个字段:书名、作者、主题和出版日期。一般来说,图书馆会有两种目录:一种按书名排序,另一种按作者姓名排序。这样,读者既可以先想到某位作家并查找其作品,也可以在不知道作者的情况下直接搜索特定书名。这些目录就类似于书籍数据库的索引,它们提供了按相关信息排序的数据列表,使查询变得更加便捷。
简单来说,索引是一种数据结构,可以看作是指向实际数据存储位置的目录。当我们在表的某一列上创建索引时,索引会存储该列的值以及指向整行数据的指针。例如,假设有一个存储书籍列表的表,以下示意图展示了在“书名”列上创建索引的结构:
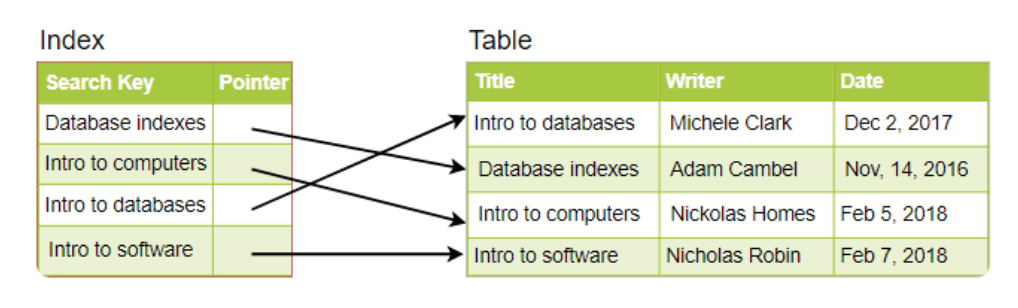
就像传统的关系型数据存储一样,我们也可以将索引概念应用到更大规模的数据集中。使用索引的关键在于,需要仔细考虑用户如何访问数据。在数据集规模达到数 TB 但单个数据负载很小(例如 1 KB)的情况下,索引对于优化数据访问至关重要。
在如此庞大的数据集中查找小型数据负载是一个巨大挑战,因为在合理的时间内不可能遍历全部数据。此外,这类大规模数据集很可能分布在多个物理设备上,因此需要某种机制来找到目标数据的物理存储位置,而索引正是实现这一目标的最佳方式。
索引如何降低写入性能?
索引能够极大加快数据检索速度,但由于需要额外存储索引键,本身可能占用较大的存储空间,同时会降低数据插入和更新的速度。
当向启用了索引的表中插入新行或更新现有行时,不仅需要写入数据,还必须更新索引结构,这会导致写入性能下降。这种影响适用于所有的插入(INSERT)、更新(UPDATE)和删除(DELETE)操作。因此,应避免在表上创建不必要的索引,并及时移除不再使用的索引。
换句话说,索引的核心目的是提升查询性能。如果数据库的主要用途是频繁写入数据,而读取较少,那么为了提升读取性能而牺牲更常见的写入操作的性能,可能并不值得。
更多详情请参考:数据库索引。