设计API限流器
我们来设计一个API限流器,用于根据用户发送请求的数量进行限流。
难度级别:中等
1. 什么是限流器?
假设我们有一个服务正在接收大量请求,但只能处理有限数量的每秒请求。为了解决这一问题,我们需要某种限流机制,允许在特定时间内仅接收一定数量的请求,以确保服务能够正常响应所有请求。
从高层次来看,限流器限制一个实体(用户、设备、IP等)在特定时间窗口内可以执行的事件数量。例如:
- 用户每秒只能发送一条消息。
- 用户每天最多允许三次信用卡交易失败。
- 单个IP每天只能创建二十个账户。
通常,限流器会限制发送方在特定时间窗口内发出的请求数量,并在达到限制时阻止后续请求。
2. 为什么需要API限流?
限流有助于保护服务免受针对应用层的滥用行为,例如拒绝服务(DOS)攻击、暴力破解密码、暴力破解信用卡交易等。这些攻击通常表现为大量的HTTP/S请求,看似来自真实用户,但通常是由机器(或机器人)生成的。因此,这些攻击通常更难被检测到,且更容易让服务、应用或API崩溃。
限流还用于防止收入损失、减少基础设施成本、阻止垃圾邮件和防止在线骚扰。以下是一些可以通过限流使服务(或API)更可靠的场景:
- 行为不当的客户端/脚本:无论是故意还是无意,一些实体可能通过发送大量请求使服务超负荷运行。另一个场景是用户发送大量低优先级的请求,我们希望确保这些请求不会影响到高优先级的流量。例如,发送大量请求以获取分析数据的用户不应妨碍其他用户的关键交易。
- 安全性:通过限制用户可以进行的二次验证尝试次数(如2FA中的错误密码尝试次数),可以有效防止暴力破解。
- 防止滥用行为和糟糕的设计实践:如果没有API限流,客户端应用的开发者可能会使用不良的开发策略,例如不断重复请求相同的信息。
- 控制成本和资源使用:服务通常是为正常的输入行为设计的,例如用户每分钟发布一条帖子。计算机可以轻松通过API推送成千上万的请求。限流器能够控制服务API的访问频率。
- 收入:某些服务可能希望根据客户服务的层级来限制操作,并基于限流创建收入模型。对于服务提供的所有API,可以设定默认的请求限制。超出限制时,用户需要购买更高的限额。
- 消除流量波动:确保服务为所有用户保持可用,避免流量尖峰影响其他用户的体验。
3. 系统的需求和目标
我们的限流器应满足以下要求:
功能需求:
- 限制实体在一个时间窗口内向API发送的请求数量,例如每秒最多15个请求。
- 由于API通过集群访问,因此限流需要跨不同服务器进行考虑。当用户在单个服务器或多个服务器的组合上超出定义的阈值时,应该返回错误信息。
非功能需求:
- 系统应具备高可用性。限流器应始终有效,因为它保护我们的服务免受外部攻击。
- 限流器不应引入显著的延迟,以免影响用户体验。
4. 如何进行限流?
限流是一个定义消费者访问API的速率和频率的过程。**限流(Throttling)**指的是在给定时间段内控制客户使用API的过程,限流可以在应用层或API层进行定义。当达到限流阈值时,服务器会返回HTTP状态码“429 - Too many requests”(请求过多)。
5. 常见的限流类型
以下是三种常见的限流类型,广泛应用于不同的服务:
硬限流(Hard Throttling):
API请求数量不能超过限流阈值。一旦达到限制,后续请求将被阻止。软限流(Soft Throttling):
允许API请求数量超过阈值的一定百分比。例如,如果限流为每分钟100条消息,且允许10%的超额限度,限流器会允许每分钟最多发送110条消息。弹性限流(Elastic/Dynamic Throttling):
当系统有可用资源时,请求数量可以超出阈值。例如,用户被允许每分钟发送100条消息,但如果系统有空闲资源,可以允许用户发送超过100条消息。
6. 用于限流的算法类型
以下是用于限流的两种算法类型:
固定窗口算法(Fixed Window Algorithm):
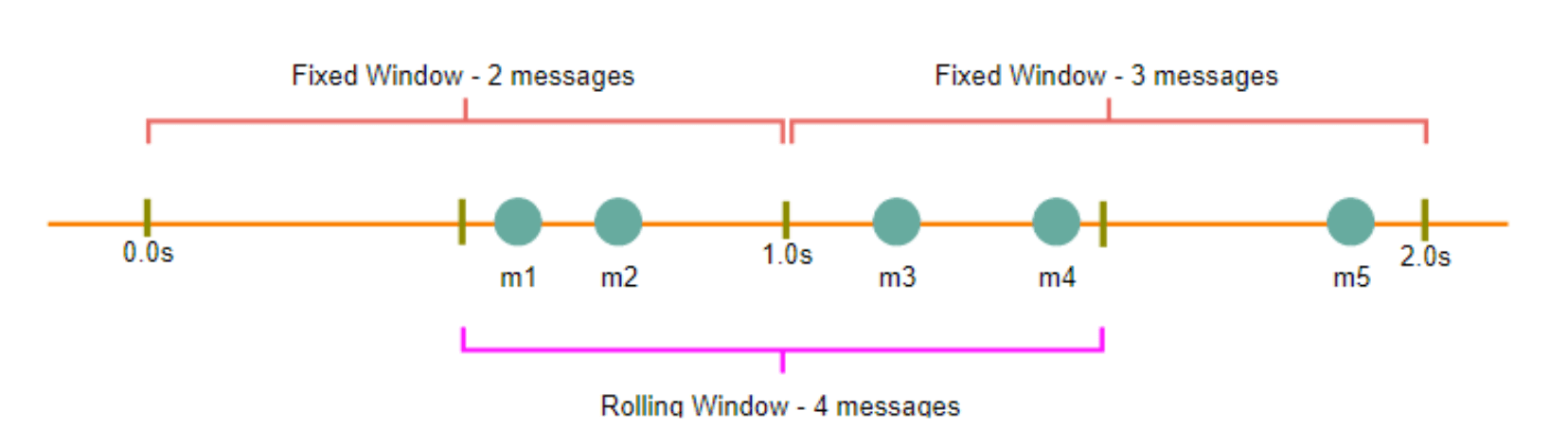
在此算法中,时间窗口以时间单位的起点到终点来衡量。例如,对于一分钟的时间段,即0-60秒,无论API请求是在该时间段的何时发送,都归入同一窗口。在下图中,0-1秒内有两条消息,1-2秒内有三条消息。如果限流为每秒两条消息,那么只有“m5”会被限流。
滑动窗口算法(Rolling Window Algorithm):
在此算法中,时间窗口从请求发生的那一刻开始计算,并持续时间窗口的长度。例如,如果在某一秒的第300毫秒和400毫秒各发送了一条消息,那么这两条消息将被统计为从该秒的300毫秒开始到下一秒的300毫秒结束这段时间内的两条消息。在上述图示中,如果限流为每秒两条消息,那么“m3”和“m4”将会被限流。
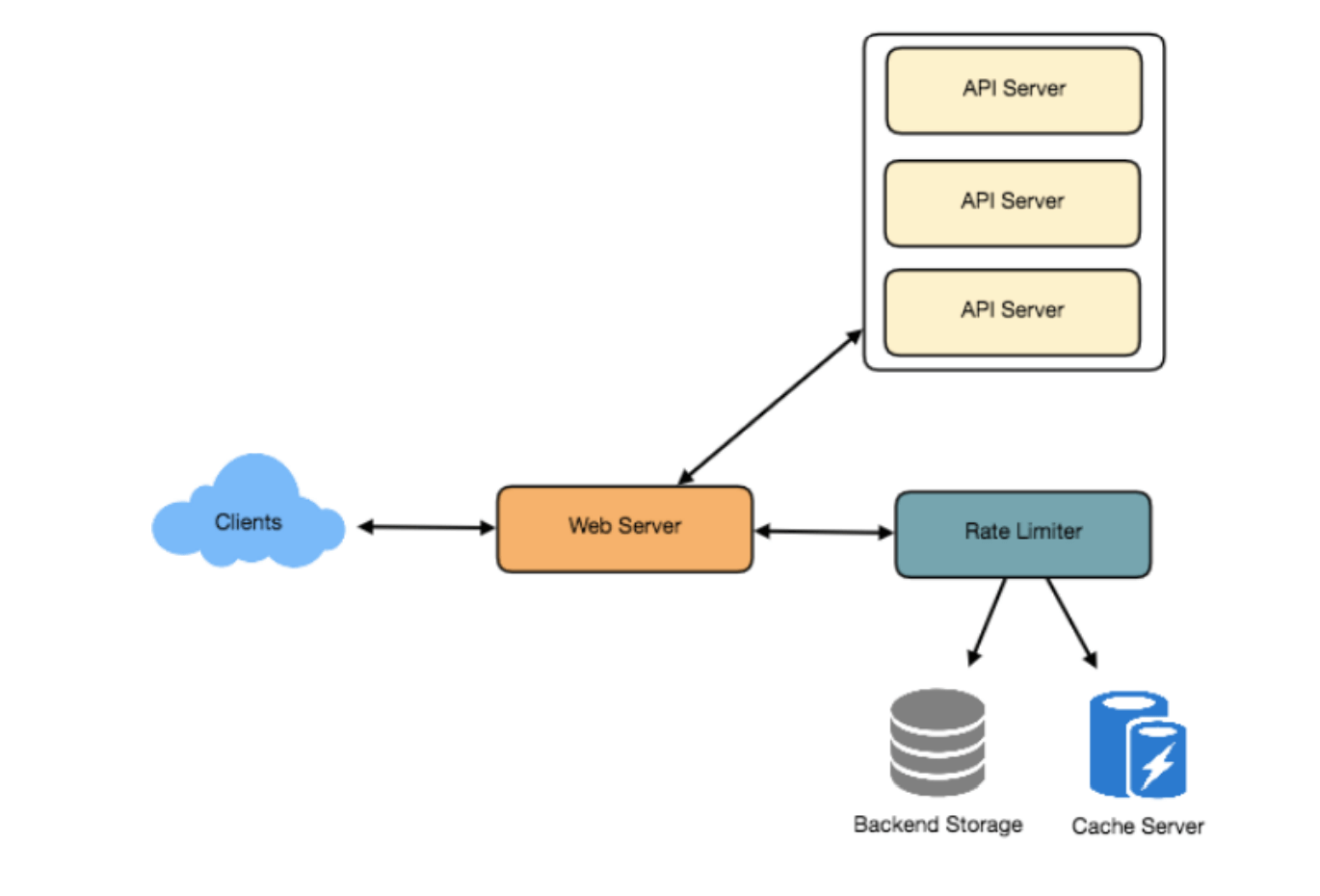
7. 限流器的高层设计
限流器将负责决定由API服务器处理的请求以及应予拒绝的请求。当新请求到达时,Web服务器首先会询问限流器该请求是被允许还是应当被限流。如果请求未被限流,则会将其传递给API服务器。
8. 基本系统设计与算法
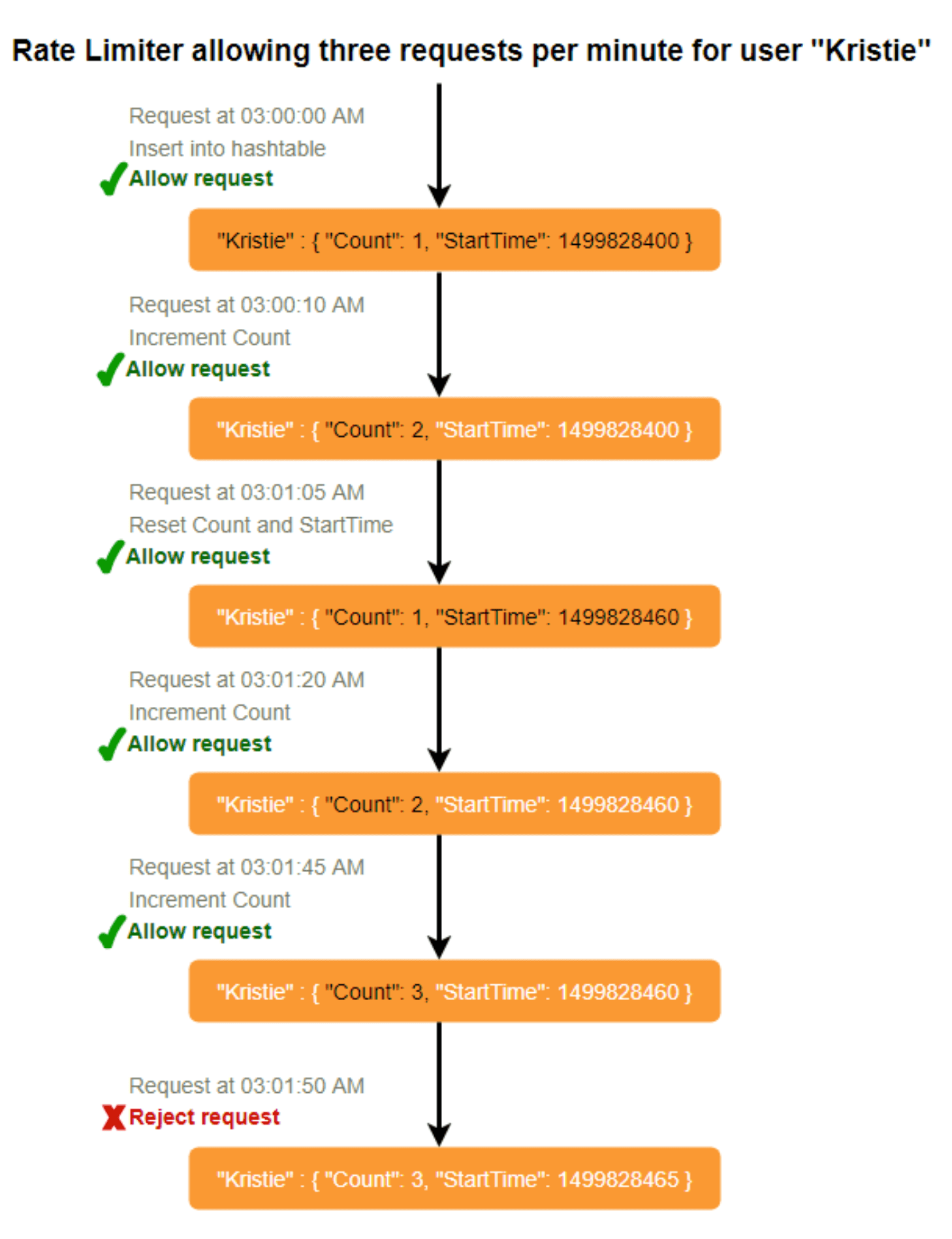
以下是一个示例场景:我们希望为每位用户限制每分钟的请求数。在这种情况下,对于每个唯一用户,我们需要维护一个计数器(表示该用户已发出的请求数)以及一个时间戳(表示开始计数的时间)。我们可以使用哈希表来实现,其中“键”(key)是用户ID(UserID),而“值”(value)是一个包含计数(Count)和起始时间(Epoch Time)的结构。
假设我们的限流器允许每位用户每分钟最多3次请求。当新请求到来时,限流器将执行以下步骤:
如果哈希表中不存在该
UserID:- 插入此
UserID记录 - 将
Count设为1 - 将
StartTime设为当前时间(归一化到分钟级别) - 允许该请求通过
- 插入此
否则(如果哈希表中已存在该
UserID记录):如果
CurrentTime – StartTime >= 1 min:- 将
StartTime重置为当前时间 - 将
Count设为1 - 允许该请求通过
- 将
如果
CurrentTime - StartTime < 1 min且:- 当
Count < 3时:- 将
Count加1 - 允许该请求通过
- 将
- 当
Count >= 3时:- 拒绝该请求
- 当
我们这套算法存在哪些问题?
- 固定窗口的局限性
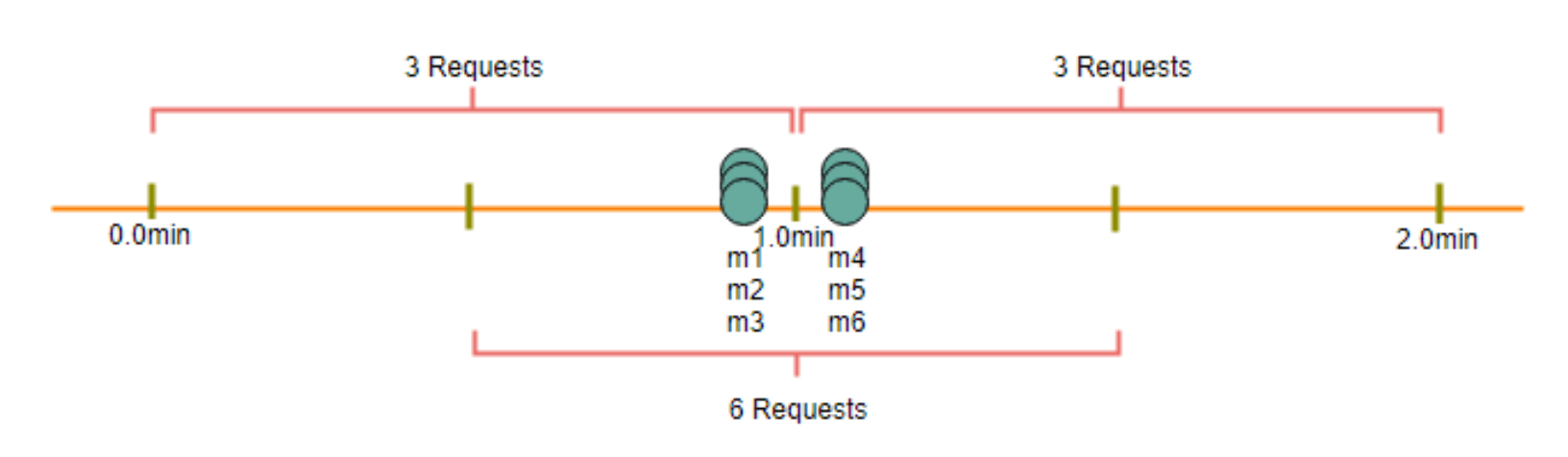
这是一个固定窗口算法,因为我们在每分钟结束后重置了“StartTime”。这种做法可能导致每分钟允许的请求数翻倍。想象一下,如果 Kristie 在某一分钟的最后一秒内发送了 3 个请求,那么她可以在下一分钟的第一秒再次发送 3 个请求,从而在两秒内总共发出 6 个请求。对此问题的解决方案是使用滑动窗口算法,我们会在后面进行讨论。
- 原子性问题
在分布式环境中,“先读后写”的操作模式会引发竞态条件。举例来说,如果 Kristie 当前的Count为 2,而她又同时发起两个新请求,如果这两个请求分别被两个并发进程处理,并且都在任一进程更新Count之前读取到了Count=2,那么每个进程都会错误地认为 Kristie 还可以再发送一次请求,导致没有正确执行限流。

如果我们使用 Redis 来存储键值数据,一种解决原子性问题的方法是在读写操作期间使用 Redis 锁。然而,这会让同一用户的并发请求被顺序化处理,降低吞吐量并增加系统复杂度。我们也可以使用 Memcached,但也同样会面临类似的复杂性。
如果我们使用简单的哈希表,可以为每条记录实现自定义的加锁机制,以解决上述的原子性问题。
假设我们将所有用户数据都存储在一个哈希表中,那么需要多少内存?
假设:
UserID占用 8 字节Count占用 2 字节(可计数到 65k,对于大多数场景足够)- Epoch 时间需要 4 字节,但如果只存储分钟和秒的部分(合并成一个 2 字节的表示方式),那么可将时间戳占用压缩到 2 字节
因此,每位用户的数据需要总共 12 字节:
8 + 2 + 2 = 12 字节假设哈希表每条记录有 20 字节的额外开销。如果需要在任意时刻跟踪 100 万(1 million)个用户,所需内存总量约为 32MB:
(12 + 20) 字节 * 1,000,000 = 32MB如果我们为了处理原子性问题,还需要给每条用户记录分配一个 4 字节的“锁”,那么总内存需求就变为 36MB。
这样看来,把所有数据存放在单台服务器的内存中是可行的;但我们并不希望所有流量都路由到一台机器上。再者,如果限流器的限制是每秒允许 10 次请求,那么限流器可能需要应对 1,000,000 用户 * 10 QPS = 10,000,000 QPS,这对于单台机器来说负载过大。
在实际中,我们可以采用 Redis 或 Memcached 等分布式方案。所有数据都会存储在远程的 Redis 服务器中,所有限流器节点在允许或拒绝请求之前,都会先去读写这些远程服务器的数据。
9. 滑动窗口算法
如果我们能够追踪每个用户的每个请求,就可以维护一个滑动窗口。我们可以将每次请求的时间戳存储在 Redis 的有序集合(Sorted Set)的哈希表的“值”字段中。
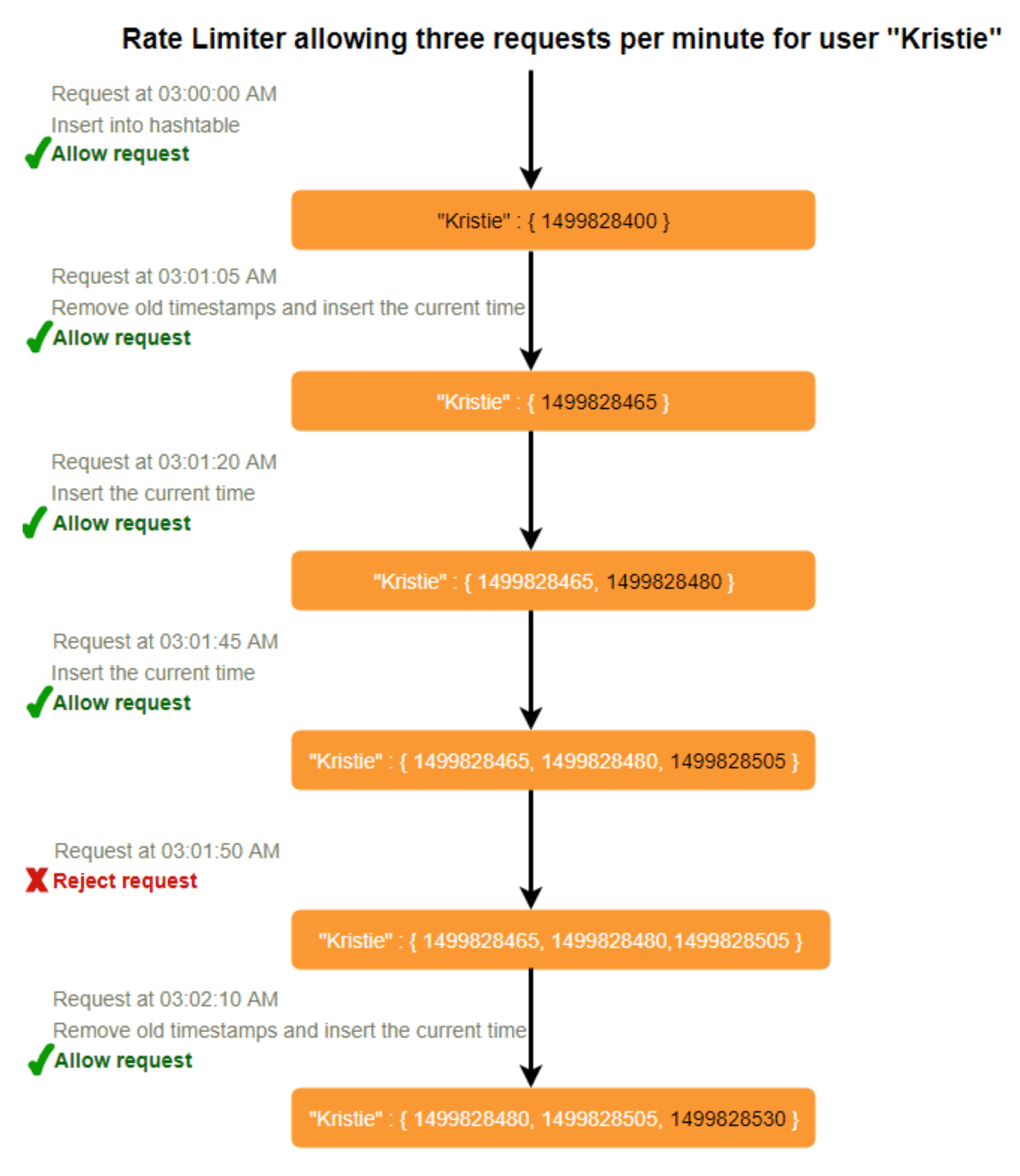
假设我们的限流器允许每个用户每分钟最多发出 3 次请求,当有新请求到达时,限流器将执行以下步骤:
- 从有序集合中移除所有早于“当前时间 - 1分钟”的时间戳。
- 统计有序集合中的元素总数。如果此计数超过我们的限流阈值“3”,则拒绝请求。
- 将当前时间插入有序集合中并接受请求。
需要多少内存来存储滑动窗口的用户数据?
假设 UserID 占用 8 字节,每个时间戳(epoch time)占用 4 字节。有序集合有 20 字节的开销,哈希表有 20 字节的开销。如果我们需要限制每小时 500 次请求,单个用户的数据总占用为 12KB:
8 + (4 + 20 (sorted set overhead)) * 500 + 20 (hash-table overhead) = 12KB其中每个元素保留了 20 字节的开销。在有序集合中,为了维护元素之间的顺序,我们需要至少两个指针:一个指向前一个元素,一个指向下一个元素。在 64 位机器上,每个指针占用 8 字节,因此需要 16 字节来存储指针。我们还添加了一个额外的字(4 字节)来存储其他开销。
如果我们需要随时追踪 100 万个用户的数据,总内存需求为 12GB:
12KB * 1 million ~= 12GB滑动窗口算法的问题
相比固定窗口算法,滑动窗口算法的内存需求更大,这可能会带来可扩展性问题。那么,如果我们结合以上两种算法,是否可以优化内存使用呢?
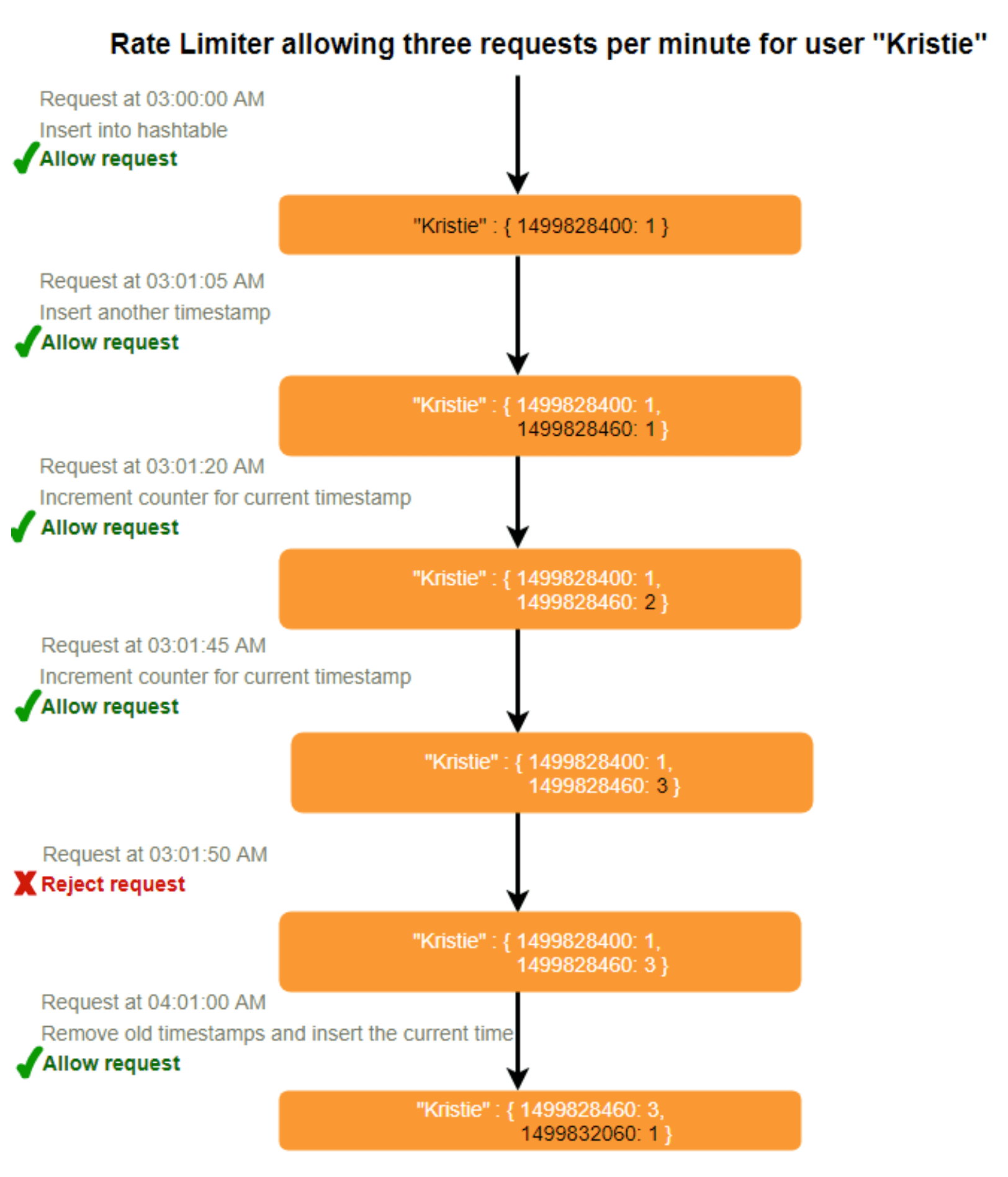
10. 基于计数器的滑动窗口
如果我们通过多个固定时间窗口追踪每个用户的请求计数,例如,将限流的时间窗口分为 1/60 的大小。例如,对于每小时限流,我们可以记录每分钟的计数,并在收到新请求时计算过去一小时内所有计数器的总和,以确定限流阈值。这将减少内存占用。假设我们每小时限流 500 次,并限制每分钟最多 10 次请求。这意味着,当时间戳在过去一小时内的计数器总和超过请求阈值(500)时,Kristie 超过了限流。此外,她每分钟不能发送超过 10 次请求。这是一个合理且实际的考量,因为真实用户不会频繁发送请求。即使他们这样做,限额每分钟重置,他们可以通过重试成功。
我们可以将计数器存储在 Redis 哈希中,因为它对少于 100 个键的存储效率极高。当每次请求递增哈希中的计数器时,同时设置哈希在一小时后过期。我们将每个“时间”归一化到分钟。
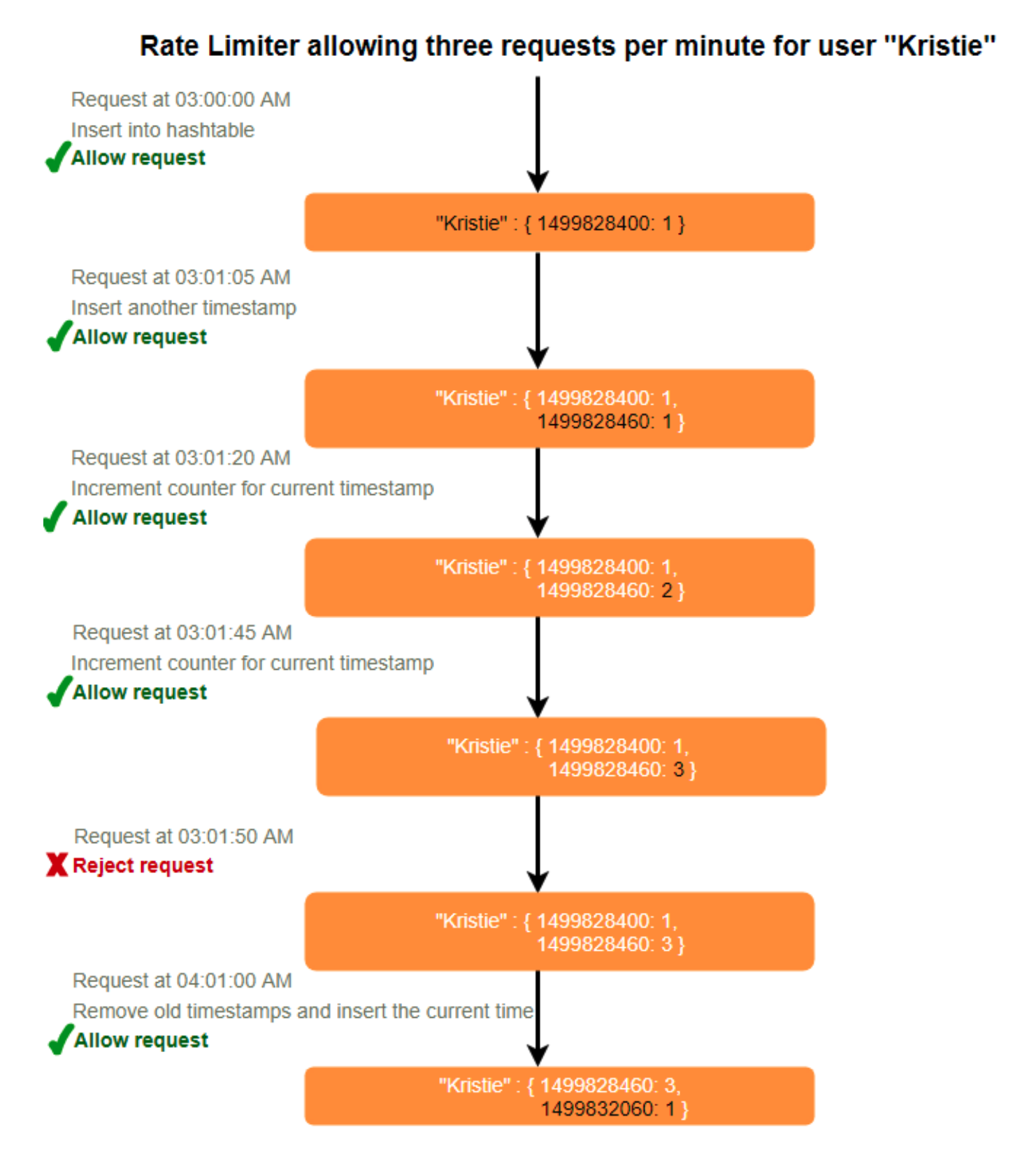
需要多少内存来存储基于计数器的滑动窗口用户数据?
假设 UserID 占用 8 字节,每个时间戳占用 4 字节,计数器占用 2 字节。假设哈希表有 20 字节开销,Redis 哈希有 20 字节开销。由于我们将为每分钟保存一个计数,每个用户最多需要 60 个条目。我们总共需要 1.6KB 来存储一个用户的数据:
8 + (4 + 2 + 20 (Redis hash overhead)) * 60 + 20 (hash-table overhead) = 1.6KB如果我们需要随时追踪 100 万个用户的请求,总内存需求为:
1.6KB * 1 million ~= 1.6GB因此,基于计数器的滑动窗口算法比单纯滑动窗口算法节省了 86% 的内存。
11. 数据分片与缓存
我们可以基于 UserID 进行分片以分配用户数据。为了实现容错和数据复制,我们应该使用一致性哈希(Consistent Hashing)。如果我们希望为不同的 API 设置不同的限流策略,可以选择基于用户和 API 进行分片。例如,在 URL 缩短器的场景中,我们可以为每个用户或 IP 分别设置 createURL() 和 deleteURL() API 的限流器。
如果我们的 API 被分区,一个实际的考虑是为每个 API 分区设置一个单独的(相对较小的)限流器。例如,在 URL 缩短器的场景中,我们希望限制每个用户每小时最多创建 100 个短链接。假设我们对 createURL() API 使用基于哈希的分区,可以对每个分区进行限流,限制用户每分钟最多创建 3 个短链接,同时每小时最多创建 100 个短链接。
我们的系统可以通过缓存最近活跃用户的记录获得巨大收益。应用服务器可以在访问后端服务器之前快速检查缓存中是否存在所需记录。我们的限流器可以显著受益于写回缓存(Write-back Cache),仅在缓存中更新所有计数器和时间戳。对永久存储的写操作可以以固定时间间隔完成。这种方式可以确保限流器对用户请求增加的延迟最小。读取操作可以始终优先访问缓存;当用户达到限额时,这种方式非常有用,因为限流器此时仅需要读取数据,而无需更新。
最近最少使用(LRU) 是我们系统中一种合理的缓存淘汰策略。
12. 应按 IP 还是用户进行限流?
以下是使用每种方案的优缺点:
按 IP
在此方案中,我们对每个 IP 的请求进行限流。尽管这种方式在区分“好”用户和“坏”用户方面并不理想,但仍然优于没有限流的情况。IP 基限流的最大问题在于多个用户可能共享一个公共 IP,例如网吧或使用同一网关的智能手机用户。一名恶意用户可能会导致其他用户被限流。此外,在缓存 IP 基限流规则时也可能出现问题,因为 IPv6 提供了巨大的地址空间,黑客甚至可以通过一台电脑生成大量 IPv6 地址,这可能导致服务器因追踪 IPv6 地址而耗尽内存。
按用户
限流可以在用户认证后的 API 上进行。一旦认证成功,用户将获得一个令牌,并在每次请求时传递该令牌。这可以确保我们对特定 API 进行限流,而该 API 仅针对具有有效认证令牌的用户。然而,如果我们需要对登录 API 本身进行限流,该方案可能存在弱点。例如,黑客可能通过输入错误的凭据达到限额,从而导致实际用户无法登录。
混合方案
一个合理的做法是同时实施按 IP 和按用户的限流,因为单独实施其中一种方案时存在缺点。不过,这种方法会导致更多的缓存条目,并且每条目需要包含更多的详细信息,从而增加内存和存储的需求。