设计一个类似YouTube的视频共享服务
类似服务:netflix.com, vimeo.com, dailymotion.com, veoh.com
难度级别:中等
1. 为什么是YouTube?
YouTube是全球最受欢迎的视频共享网站之一。用户可以在平台上上传、观看、分享、评分和举报视频,还可以在视频下添加评论。
2. 系统的需求和目标
为了简化设计,以下是我们要构建的一个简化版YouTube的需求:
功能性需求:
- 用户应能上传视频。
- 用户应能分享和观看视频。
- 用户应能根据视频标题进行搜索。
- 系统应能记录视频的统计数据,例如点赞/点踩数量、观看次数等。
- 用户应能在视频下添加和查看评论。
非功能性需求:
- 系统应具有高可靠性,确保任何上传的视频都不会丢失。
- 系统应具有高可用性。为了保证可用性,允许牺牲一定程度的一致性;若用户暂时无法看到某个视频,可以接受。
- 用户在观看视频时应有实时体验,不应感到任何延迟。
不在范围内: 视频推荐、最受欢迎的视频、频道、订阅、稍后观看、收藏夹等功能。
3. 容量估算与约束
假设我们有15亿总用户,其中8亿是日活跃用户。如果平均每个用户每天观看5个视频,那么总视频观看量每秒将为:
800M * 5 / 86400秒 ≈ 46K视频/秒
假设我们的视频上传与观看比为1:200,即每上传一个视频有200次观看,这样每秒有230个视频上传:
46K / 200 ≈ 230视频/秒
存储估算:假设每分钟有500小时的视频上传到YouTube。如果平均每分钟视频需要50MB的存储空间(视频需要存储为多种格式),那么每分钟上传视频所需的总存储量为:
500小时 * 60分钟 * 50MB ≈ 1500 GB/分钟(25 GB/秒)
以上估算未考虑视频压缩和复制,这些因素会影响我们的估算结果。
带宽估算:每分钟上传500小时视频,假设每分钟的视频上传占用10MB带宽,我们每分钟的上传量将为300GB:
500小时 * 60分钟 * 10MB ≈ 300GB/分钟(5GB/秒)
假设上传与观看的比率为1:200,我们每秒需要1TB的输出带宽。
4. 系统API
我们可以使用SOAP或REST API来暴露服务的功能。以下是上传和搜索视频API的定义:
uploadVideo(api_dev_key, video_title, video_description, tags[], category_id, default_language, recording_details, video_contents)上传API参数:
api_dev_key(string):已注册账号的API开发密钥,用于限制用户访问频率,基于其分配的配额。video_title(string):视频标题。video_description(string):视频的可选描述。tags(string[]):视频的可选标签。category_id(string):视频类别,例如电影、歌曲、人物等。default_language(string):视频语言,例如英语、普通话、印地语等。recording_details(string):视频录制的地点。video_contents(stream):要上传的视频内容。
返回: (string)
成功上传会返回HTTP 202(请求已接受),视频编码完成后,系统通过电子邮件通知用户,并提供访问视频的链接。我们还可以提供可查询的API,让用户了解其上传视频的当前状态。
searchVideo(api_dev_key, search_query, user_location, maximum_videos_to_return, page_token)搜索API参数:
api_dev_key(string):已注册账号的API开发密钥。search_query(string):包含搜索词的字符串。user_location(string):执行搜索的用户位置(可选)。maximum_videos_to_return(number):单次请求返回的最大结果数量。page_token(string):用于指定应返回结果集中的某一页面的标记。
返回: (JSON)
返回包含与搜索查询匹配的视频资源列表的JSON。每个视频资源包括视频标题、缩略图、视频创建日期和观看次数。
streamVideo(api_dev_key, video_id, offset, codec, resolution)流媒体API参数:
api_dev_key(string):已注册账号的API开发密钥。video_id(string):视频的标识字符串。offset(number):允许从视频的任何偏移位置流式播放,此偏移量为从视频开始的秒数。如果支持在多个设备上播放/暂停视频,则需要在服务器上存储该偏移量,使用户在任意设备上从上次观看的时间点继续播放视频。codec(string) &resolution(string):客户端API需传递编解码器和分辨率信息,以支持多个设备的播放/暂停功能。例如,当用户在电视的Netflix应用上观看视频时暂停,再切换到手机上的Netflix应用继续观看,此时需要编解码器和分辨率信息,因为不同设备的分辨率和使用的编解码器不同。
返回: (STREAM)
从指定的偏移位置开始的视频媒体流(视频片段)。
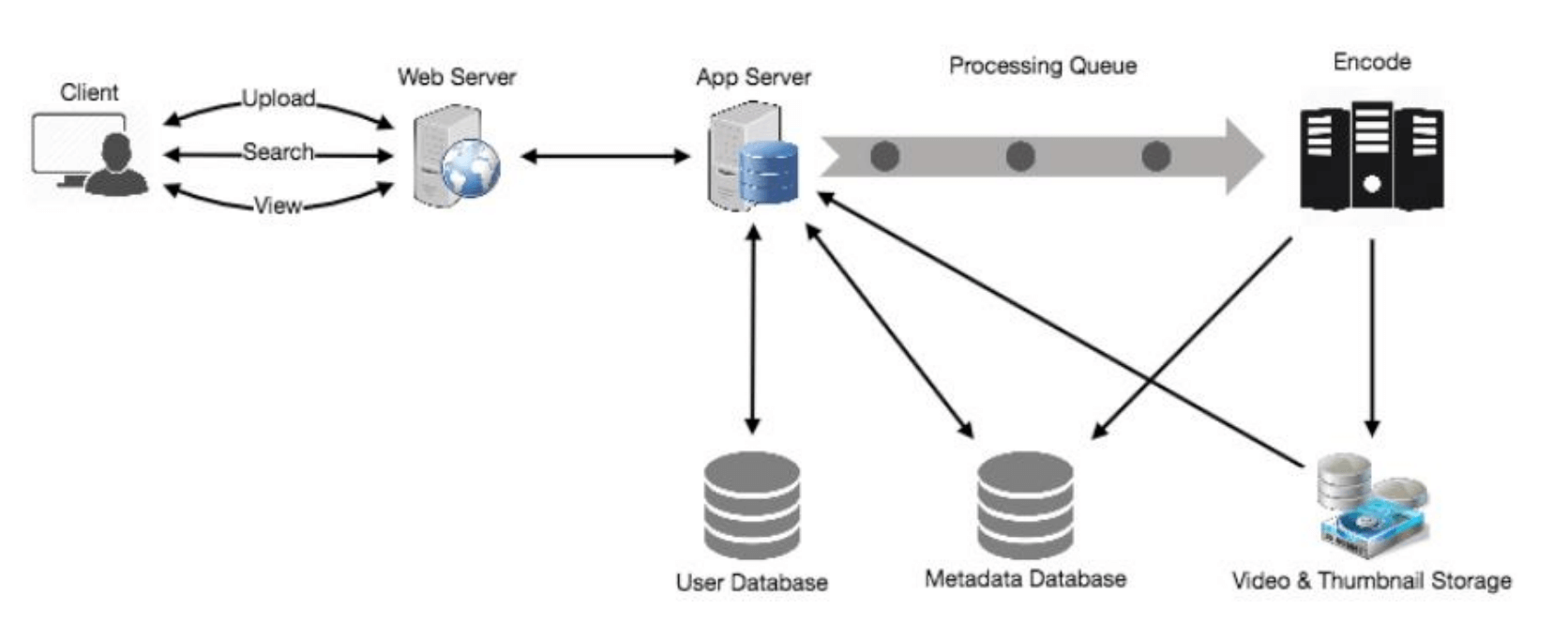
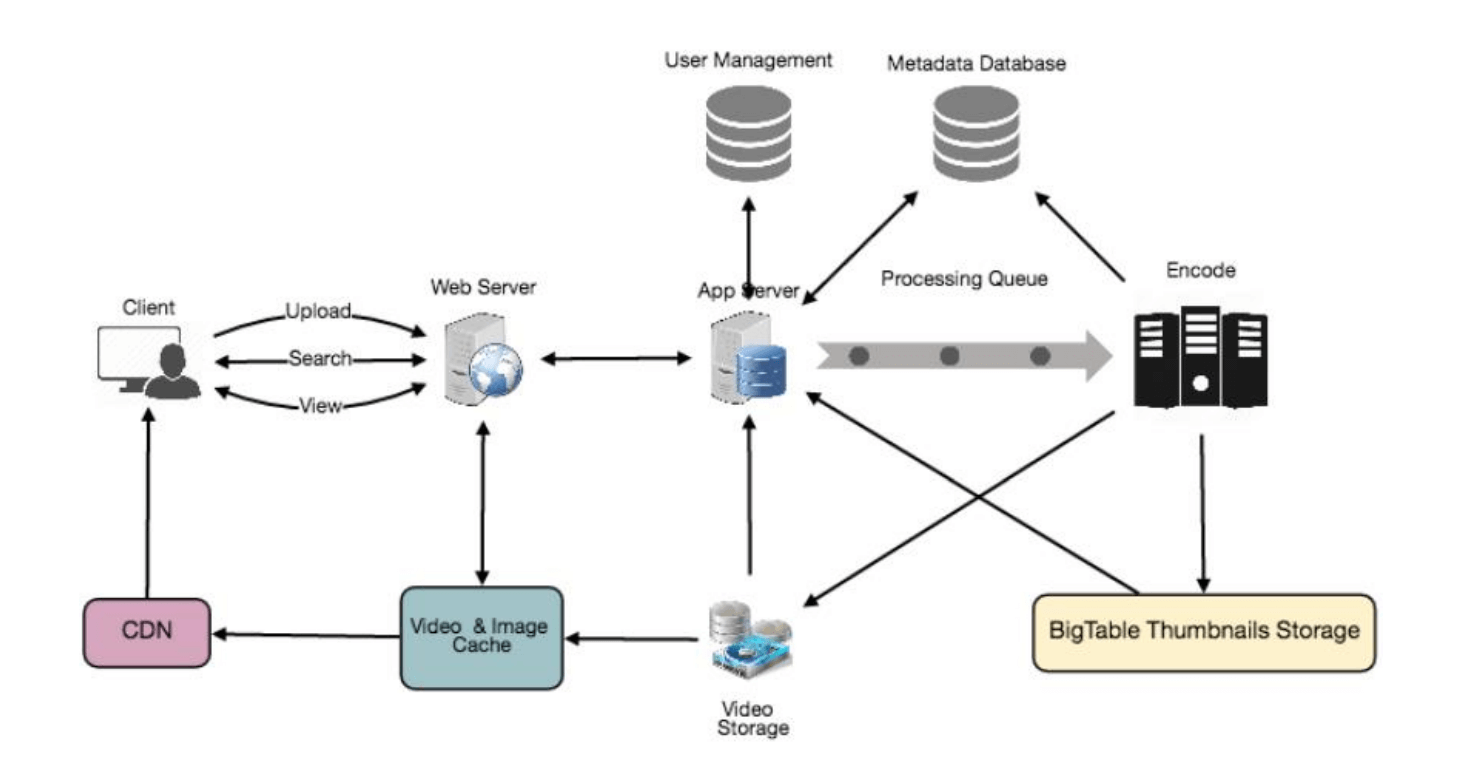
5. 高层设计
从高层次来看,我们需要以下组件:
- 处理队列:每个上传的视频将被推送到处理队列中,稍后会从队列中取出进行编码、缩略图生成和存储。
- 编码器:用于将每个上传的视频编码为多种格式。
- 缩略图生成器:用于为每个视频生成几个缩略图。
- 视频和缩略图存储:用于将视频和缩略图文件存储在分布式文件存储系统中。
- 用户数据库:用于存储用户信息,例如姓名、电子邮件、地址等。
- 视频元数据存储:一个元数据库,用于存储关于视频的所有信息,如标题、系统中的文件路径、上传用户、总观看次数、点赞、点踩等。同时,也用于存储所有视频评论。
6. 数据库模式
视频元数据存储 - MySQL
视频的元数据可以存储在SQL数据库中,需要为每个视频存储以下信息:
VideoID:视频唯一标识符Title:视频标题Description:视频描述Size:视频文件大小Thumbnail:缩略图路径Uploader/User:上传者/用户Total number of likes:总点赞数Total number of dislikes:总点踩数Total number of views:总观看次数
每条视频评论需要存储以下信息:
CommentID:评论唯一标识符VideoID:关联的视频标识符UserID:发表评论的用户标识符Comment:评论内容TimeOfCreation:评论创建时间
用户数据存储 - MySQL
需要存储以下用户信息:
UserID:用户唯一标识符Name:用户名Email:电子邮件Address:地址Age:年龄Registration details:注册信息等
7. 详细组件设计
该服务以读操作为主,因此我们将专注于构建一个能够快速检索视频的系统。预计读写比为200:1,这意味着每上传一个视频,会有200次视频观看。
视频存储在哪里?
视频可以存储在分布式文件存储系统中,例如 HDFS 或 GlusterFS。
如何高效管理读流量?
需要将读流量与写流量分离。由于每个视频会有多份副本,可以将读流量分布到不同的服务器上。对于元数据,可以使用主从配置,写操作会首先写入主节点,然后同步到所有从节点。这种配置可能导致数据短暂的不一致,例如,当新增视频时,其元数据会先插入主节点,在同步到从节点之前,从节点无法看到该数据,因此会向用户返回过时结果。然而,这种不一致性是可以接受的,因为它持续时间很短,用户将在几毫秒后看到新视频。
缩略图存储在哪里?
缩略图数量远多于视频。如果假设每个视频有五张缩略图,则需要一个非常高效的存储系统来处理巨大的读流量。在决定使用哪种存储系统存储缩略图之前,需要考虑以下两点:
- 缩略图是小文件,每个文件最大约为 5KB。
- 缩略图的读流量远高于视频。用户一次只观看一个视频,但可能会查看包含其他视频的 20 张缩略图的页面。
如果将所有缩略图存储在磁盘上,由于文件数量庞大,读取这些文件需要频繁进行磁盘寻道操作,这是非常低效的,会导致更高的延迟。
Bigtable 是一个合理的选择,因为它将多个文件合并为一个块存储在磁盘上,在读取少量数据时非常高效。这两个特点正好满足我们的服务需求。将热门缩略图缓存起来也能帮助减少延迟。由于缩略图文件体积较小,可以轻松在内存中缓存大量此类文件。
视频上传:由于视频可能非常大,如果上传过程中连接中断,系统应支持从断点继续上传。
视频编码:新上传的视频会存储在服务器上,同时添加一个新任务到处理队列,将视频编码为多种格式。编码完成后,上传者会收到通知,视频即可用于观看或分享。
8. 元数据分片
由于每天会有大量新视频产生,同时我们的读取负载非常高,因此我们需要将数据分布到多台机器上,以高效地执行读写操作。以下是几种分片策略的讨论:
基于用户ID的分片:
我们可以尝试将特定用户的所有数据存储在一台服务器上。在存储时,可以将用户ID传递给哈希函数,由其将该用户映射到某个数据库服务器,然后在该服务器上存储该用户视频的所有元数据。在查询某个用户的视频时,可以通过哈希函数定位保存该用户数据的服务器,然后从中读取数据。
然而,这种方法存在以下问题:
- 如果某个用户变得非常受欢迎,存储该用户数据的服务器可能会因大量查询而成为性能瓶颈,从而影响整个服务的性能。
- 随着时间推移,一些用户可能会存储大量视频,而其他用户的存储量较少,这使得维持用户数据的均匀分布变得极具挑战性。
为解决上述问题,可以通过重新分区/重新分布数据或采用一致性哈希在服务器之间平衡负载。
基于视频ID的分片:
我们可以使用哈希函数将每个视频ID映射到一个随机服务器,并在该服务器上存储对应视频的元数据。要查询某个用户的视频,需要查询所有服务器,每台服务器返回一组视频,随后由中心化服务器对这些结果进行聚合和排序,再返回给用户。这种方法解决了热门用户的问题,但却将问题转移到热门视频上。
为了进一步提升性能,可以在数据库服务器前引入缓存来存储热门视频。
9. 视频去重
随着大量用户上传海量视频数据,我们的服务需要处理广泛的重复视频问题。这些重复视频可能在纵横比或编码上有所不同,可能包含叠加内容或额外边框,或者只是较长原始视频的片段。重复视频会在以下方面产生影响:
- 数据存储: 存储同一视频的多份副本会浪费存储空间。
- 缓存效率: 重复视频会占用缓存空间,从而降低缓存的利用率。
- 网络使用: 重复视频会增加需要传输到网络缓存系统的数据量。
- 能耗: 更多的存储需求、低效的缓存和高网络流量会导致能源浪费。
对于最终用户,这些低效表现为搜索结果中出现重复内容、更长的视频启动时间以及中断的流媒体播放。
从服务的角度看,尽早进行去重是更合理的选择。在用户上传视频时进行去重处理比事后处理更高效。实时去重可以节省大量资源,例如用于编码、传输和存储重复视频的资源。
当用户开始上传视频时,服务可以运行视频匹配算法(例如Block Matching、Phase Correlation等)来检测重复内容。如果发现该视频已有副本,我们可以选择中止上传并使用现有副本,或者继续上传并使用新上传的视频(若其质量更高)。如果新上传的视频是现有视频的一部分或反之,我们可以智能地将视频划分为更小的块,仅上传缺失的部分。
10. 负载均衡
我们应该在缓存服务器中使用一致性哈希,以在缓存服务器之间实现负载均衡。由于我们采用基于静态哈希的方案将视频映射到主机名,可能会因视频受欢迎程度的不同导致逻辑副本负载不均。例如,如果某个视频变得非常受欢迎,映射到该视频的逻辑副本将承受比其他服务器更多的流量。这种逻辑副本的负载不均会进一步导致对应物理服务器的负载分布不均。
为解决此问题,某个位置的繁忙服务器可以将客户端重定向到同一缓存位置中较不繁忙的服务器。我们可以为此场景使用动态HTTP重定向。
然而,重定向也有其缺点:
- 如果接收重定向的主机无法提供视频服务,可能导致多次重定向。
- 每次重定向都需要客户端发起额外的HTTP请求,增加了视频开始播放前的延迟。
- 跨层级(或跨数据中心)的重定向可能将客户端引导至远距离缓存位置,因为高层缓存通常只存在于少数地点。
11. 缓存
为了服务全球分布的用户,我们的系统需要一个大规模视频分发系统。通过大量地理分布的视频缓存服务器,将内容推送至离用户更近的地方,可以显著提高用户性能并均衡缓存服务器的负载。
我们可以在元数据服务器中引入缓存,用于缓存热门数据库行。通过在访问数据库前使用Memcache缓存数据和应用服务器,可以快速检查缓存中是否存在所需的数据行。对于缓存淘汰策略,**最近最少使用(LRU)**是一种合理的选择,该策略优先丢弃最近未访问的数据行。
如何构建更智能的缓存?依据80-20法则,即20%的每日视频读取量会产生80%的流量,表明某些视频的受欢迎程度极高,绝大多数用户观看的是这些热门视频。因此,我们可以尝试缓存每日读取量的20%的视频和元数据。
12. 内容分发网络 (CDN)
CDN是一种分布式服务器系统,通过用户的地理位置、网页来源和内容分发服务器的关系向用户交付网络内容。请参考“缓存”章节中的“CDN”部分。
我们的服务可以将热门视频移至CDN:
- CDN在多个地点复制内容,使视频更接近用户。通过减少跳转次数,视频可以通过更友好的网络流进行流式传输。
- CDN服务器广泛使用缓存,大多数情况下可以直接从内存中提供视频。
不太热门的视频(每天1-20次观看)如果未被CDN缓存,可以由我们在各数据中心的服务器提供服务。
13. 故障容错
在数据库服务器之间分布数据时,我们应该使用一致性哈希。一致性哈希不仅可以在服务器失效时替换故障服务器,还能帮助服务器之间均衡负载。