分布式系统的关键特性
分布式系统的关键特性包括可扩展性(Scalability)、可靠性(Reliability)、可用性(Availability)、效率(Efficiency)和可管理性(Manageability)。下面我们简要介绍这些特性:
可扩展性(Scalability)
可扩展性指的是系统、进程或网络能够扩展并处理不断增长的需求。任何能够持续扩展以支持更大工作负载的分布式系统都被认为是可扩展的。
系统可能需要扩展的原因有很多,例如数据量的增加或工作负载的增长(如事务数量的增加)。理想情况下,一个可扩展的系统应当能够实现扩展而不降低性能。
尽管某些系统在设计上(或声称)是可扩展的,但通常随着系统规模的增长,其性能会下降,这是由于管理开销或环境因素的影响。例如,网络速度可能会变慢,因为服务器之间的物理距离增大。此外,某些任务可能无法被分布式执行,要么是由于其本质上的原子性(atomic nature),要么是由于系统设计上的缺陷。在某些情况下,这类任务会成为系统扩展的瓶颈,限制分布式计算所能带来的加速效果。一个良好的可扩展架构能够避免这种情况,并尝试在所有参与节点之间均衡负载。
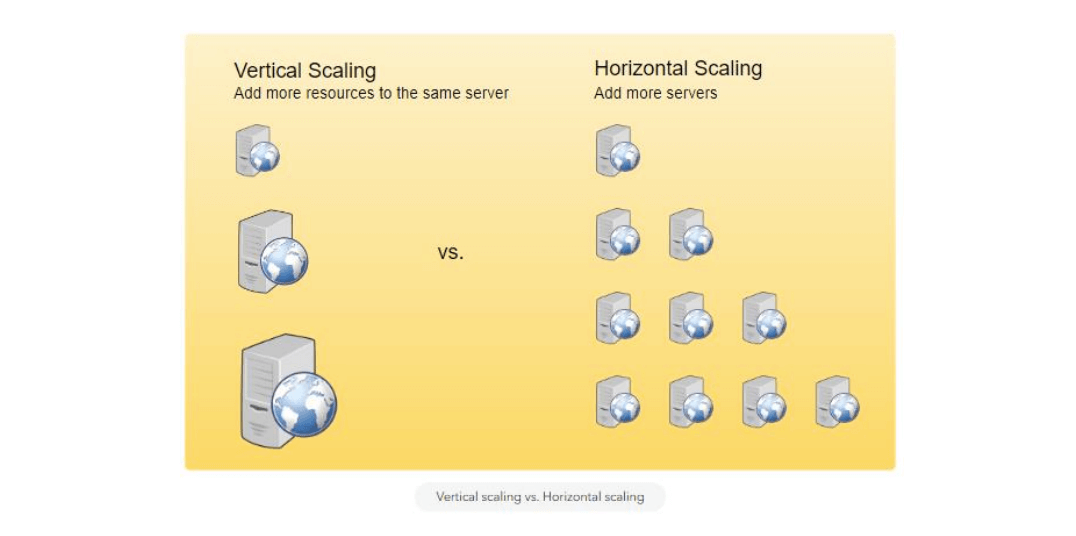
横向扩展 vs. 纵向扩展
- 横向扩展(Horizontal Scaling):通过增加更多服务器来扩展资源池。
- 纵向扩展(Vertical Scaling):通过向现有服务器增加计算资源(CPU、RAM、存储等)来扩展。
横向扩展通常更容易进行动态扩展,只需向现有集群中添加新机器即可。而纵向扩展通常受限于单台服务器的硬件能力,超出该限制的扩展通常需要停机,并且存在上限。
示例:
- 横向扩展的典型案例是 Cassandra 和 MongoDB,它们支持通过增加更多机器来轻松满足增长的需求。
- 纵向扩展的典型案例是 MySQL,可以通过升级到更高性能的服务器来扩展,但这一过程通常需要停机。
可靠性(Reliability)
从定义上讲,可靠性是指系统在特定时间内发生故障的概率。简单来说,一个分布式系统如果在某些软件或硬件组件发生故障时仍能继续提供服务,那么它就是可靠的。
可靠性是分布式系统的核心特性之一,因为在这些系统中,任何出现故障的机器都可以被另一台正常运行的机器替代,以确保请求任务得以完成。
例如,在一个大型电子商务平台(如 Amazon)中,用户交易绝不能因运行该交易的服务器故障而被取消。例如,如果用户将商品加入购物车,系统必须确保不会丢失该信息。一个可靠的分布式系统通过软件组件和数据的冗余来实现这一点。如果存储购物车数据的服务器发生故障,另一台保存该购物车数据副本的服务器应该立即接管服务。
当然,冗余是有成本的,一个可靠的系统需要付出代价来消除单点故障,从而提高服务的容错能力。
可用性(Availability)
可用性定义为系统在特定时间段内保持正常运行并执行其预期功能的时间比例。它通常用系统、服务或设备在正常条件下可用的时间占比来衡量。例如,一架飞机如果在一个月内能长时间飞行且停机时间很少,那么它被认为具有高可用性。
可用性涉及多个因素,如可维护性、修复时间、备件供应情况以及其他后勤保障。例如,如果一架飞机因维护而停飞,那么在此期间它被认为是不可用的。
可靠性可以被视为可用性的长期表现,它考虑了系统在现实世界中可能遇到的所有情况。例如,一架飞机如果能够在任何天气条件下安全飞行,那么它比只能在良好天气条件下飞行的飞机更可靠。
可靠性 vs. 可用性
如果一个系统是可靠的,那么它一定是可用的。但如果一个系统是可用的,它却不一定是可靠的。换句话说,高可靠性有助于提高可用性,但即使产品本身不可靠,也可以通过缩短修复时间和确保备件充足来实现高可用性。
例如,假设一个在线零售网站在上线后的前两年可用性高达 99.99%,但它在发布时没有进行任何信息安全测试。用户在使用时可能感觉系统运行良好,但实际上它存在严重的安全漏洞。因此,在第三年,系统经历了一系列信息安全事件,导致长时间不可用,最终造成声誉和财务损失。
效率(Efficiency)
在衡量分布式系统的效率时,我们可以假设有一个分布式执行的操作,该操作会返回一组结果项。衡量其效率的两个标准指标是:
- 响应时间(Response Time)或延迟(Latency):指获取第一个结果项所需的时间。
- 吞吐量(Throughput)或带宽(Bandwidth):指在给定时间单位(如每秒)内传输的结果项数量。
这两个指标对应于以下单位成本:
- 全局发送的消息数(所有节点发送的消息总量,而不考虑单个消息的大小)。
- 消息的大小(表示数据交换的总量)。
衡量分布式数据结构支持的操作复杂度(例如,在分布式索引中查找特定键),通常可以用这些成本单位的函数来表示。
通常,仅从消息数量来分析分布式系统的效率是过于简化的。这种方法忽略了许多关键因素,例如:
- 网络拓扑结构
- 网络负载及其变化
- 数据处理和路由过程中涉及的软件与硬件的异构性
然而,构建一个能精确考虑所有这些性能因素的成本模型是非常困难的。因此,我们只能接受一些粗略但稳健的系统性能估算方法。
可维护性(Serviceability)或可管理性(Manageability)
在设计分布式系统时,另一个重要的考虑因素是系统的易操作性和可维护性。
可维护性(Serviceability)或可管理性(Manageability)指的是系统的维护或修复的简便性和速度。如果修复失败系统所需的时间增加,那么系统的**可用性(Availability)**将会降低。
影响可管理性的因素包括:
- 问题诊断与理解的难易程度(出现故障时,是否容易定位和分析问题?)
- 更新或修改的便捷性(是否可以轻松进行系统升级或调整?)
- 系统的操作简便性(系统是否能长期稳定运行,而不会频繁出现异常或故障?)
及早发现故障可以减少或避免系统停机时间。例如,一些企业级系统可以在发生故障时自动联系服务中心(无需人工干预),从而缩短修复时间,提高系统的可用性。