设计 Yelp 或附近的朋友
我们来设计一个类似 Yelp 的服务,用户可以搜索附近的地点,如餐馆、剧院或购物中心等,并可以添加/查看这些地点的评论。
类似服务:邻近服务器(Proximity Server)
难度级别:困难
1. 为什么是 Yelp 或邻近服务器?
邻近服务器用于发现附近的景点,如场所、活动等。如果你以前没有使用过 yelp.com,请在继续之前试用一下(你可以搜索附近的餐馆、剧院等),并花些时间了解网站提供的不同功能。这将有助于更好地理解本章内容。
2. 系统的需求和目标
我们希望从类似 Yelp 的服务中实现哪些功能?
该服务将存储不同地点的信息,以便用户可以搜索它们。当用户查询时,我们的服务将返回用户周围的地点列表。
功能性需求
- 用户应该能够 添加/删除/更新 地点。
- 根据用户的位置(经度/纬度),系统应该能够在给定半径内找到所有附近的地点。
- 用户应该能够 添加反馈/评论,包括图片、文本和评分。
非功能性需求
- 用户应当能获得 实时搜索体验,搜索延迟应尽可能低。
- 该服务应支持 高并发搜索,搜索请求的数量将远远超过新增地点的请求。
3. 规模估算
假设系统存储 5 亿(500M)个地点,并且每秒需要处理 10 万(100K)次查询请求(QPS)。此外,我们假设地点数量和查询请求量每年增长 20%。
4. 数据库模式设计
每个地点(Location)可包含以下字段:
| 字段 | 数据类型 | 大小(字节) | 说明 |
|---|---|---|---|
| LocationID | 8 bytes | 8 | 唯一标识一个地点 |
| Name | 256 bytes | 256 | 地点名称 |
| Latitude | 8 bytes | 8 | 纬度 |
| Longitude | 8 bytes | 8 | 经度 |
| Description | 512 bytes | 512 | 地点描述 |
| Category | 1 byte | 1 | 分类(如咖啡店、餐馆、剧院等) |
尽管一个 4 字节 的数值足以唯一标识 5 亿个地点,但考虑到未来的增长,我们采用 8 字节 的 LocationID。
总大小:
8 + 256 + 8 + 8 + 512 + 1 = 793 字节
此外,我们需要存储地点的 评论、照片和评分。可以使用单独的表来存储地点的评论信息:
| 字段 | 数据类型 | 大小(字节) | 说明 |
|---|---|---|---|
| LocationID | 8 bytes | 8 | 关联的地点 ID |
| ReviewID | 4 bytes | 4 | 唯一标识评论(假设单个地点不会超过 2³² 条评论) |
| ReviewText | 512 bytes | 512 | 评论内容 |
| Rating | 1 byte | 1 | 评分(10 分制) |
同样,我们可以使用单独的表来存储 地点和评论的照片。
5. 系统 API
我们可以使用 SOAP 或 REST API 来公开服务的功能。以下是搜索 API 的定义:
search(api_dev_key, search_terms, user_location, radius_filter, maximum_results_to_return, category_filter, sort, page_token)参数:
- api_dev_key (string):注册账户的 API 开发密钥。用于限制用户访问,确保其在分配的配额范围内。
- search_terms (string):包含搜索关键词的字符串。
- user_location (string):执行搜索的用户位置。
- radius_filter (number, 可选):搜索半径(单位:米)。
- maximum_results_to_return (number):要返回的商家结果数量。
- category_filter (string, 可选):用于筛选搜索结果的类别,例如“餐厅”、“购物中心”等。
- sort (number, 可选):排序模式:
- 0(默认):最佳匹配
- 1:最短距离
- 2:最高评分
- page_token (string):指定要返回的结果页的标识符。
返回值:(JSON)
返回一个 JSON,其中包含与搜索查询匹配的商家列表。每个结果条目包括商家名称、地址、类别、评分和缩略图。
6. 基本的系统设计与算法
从高层次来看,我们需要存储和索引上述各类数据集(地点、评论等)。为了让用户查询这个庞大的数据库,索引的读取性能必须足够高效,因为在搜索附近地点时,用户期望能实时看到结果。
由于地点的位置通常不会频繁变化,因此我们无需担心数据的频繁更新。但如果我们要构建一个涉及位置频繁变化的服务(例如人员或出租车的实时位置追踪),那么设计方案可能会大不相同。
接下来,我们来探讨存储这些数据的不同方法,并找出哪种方式最适合我们的需求。
a. SQL 解决方案
一个简单的方案是使用 MySQL 等数据库来存储所有数据。每个地点存储在一行数据中,并通过 LocationID 唯一标识。经度和纬度分别存储在两个独立的列中,为了加快查询速度,我们需要在这两个字段上建立索引。
要查找给定位置 (X, Y) 半径 D 内的所有地点,我们可以执行如下查询:
select * from places where Latitude between X-D and X+D and Longitude between Y-D and Y+D然而,上述查询并不完全准确。根据数学原理,要计算两点之间的距离,我们需要使用 距离公式(勾股定理),但为了简化,我们暂且使用这个方法。
那么,这个查询的效率如何?
我们的服务预计要存储 5 亿个地点。由于经度和纬度分别建立了索引,每个索引可能会返回一个庞大的地点列表,而在这些列表上执行 交集操作 并不高效。
换个角度来看,坐标范围 X-D 到 X+D 之间可能包含过多地点,同样 Y-D 到 Y+D 之间的地点数量也可能过多。如果我们能设法缩小这些列表的规模,就可以提升查询性能。
b. 网格 (Grids)
我们可以将整张地图划分为较小的网格,将位置分组成更小的集合。
每个网格将存储位于特定经纬度范围内的所有地点(Places)。这种方案使得我们只需查询少数几个网格,就能找到附近的地点。基于给定的位置和半径,我们可以找到所有相邻的网格,然后查询这些网格以找到附近的地点。
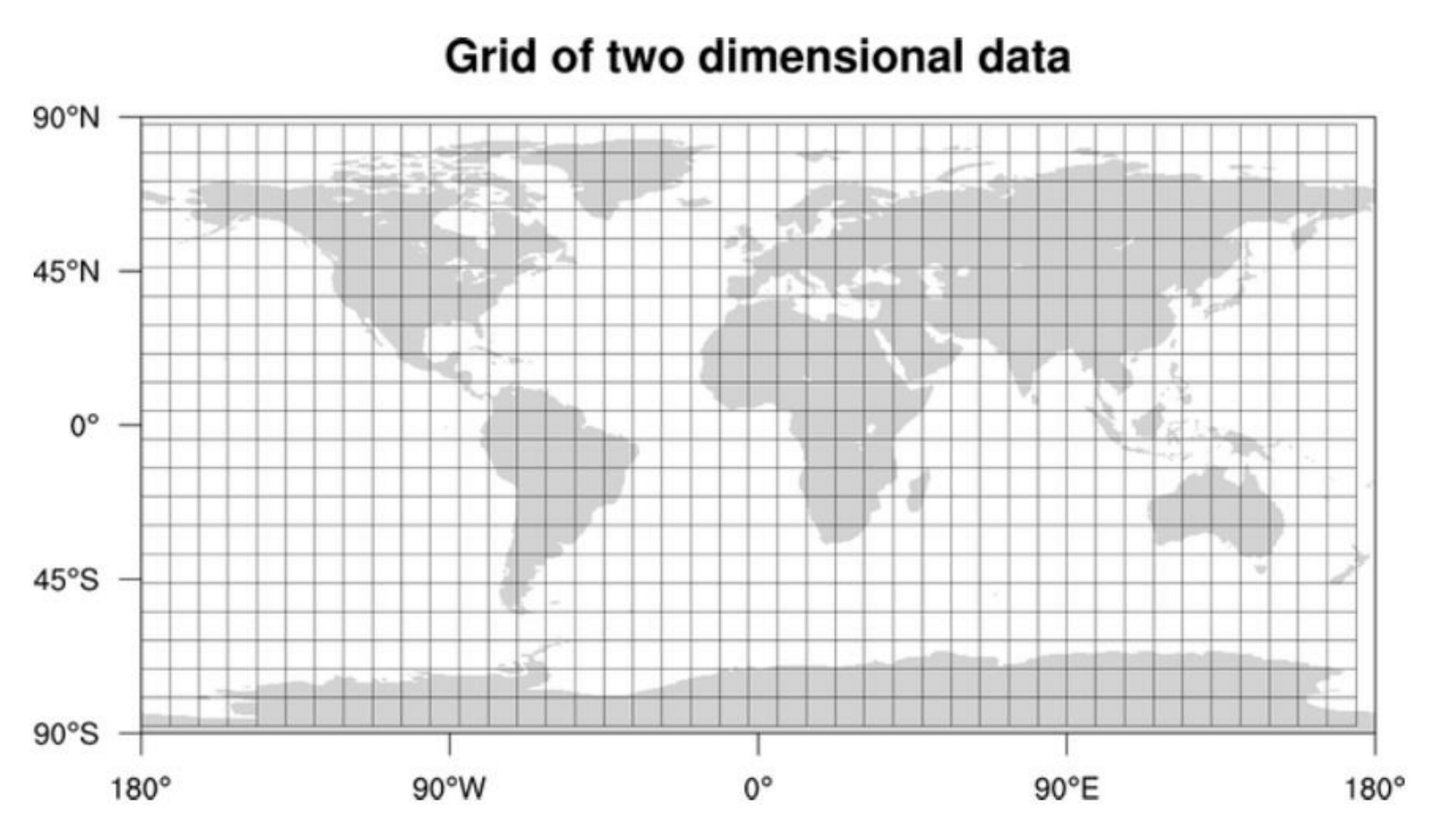
假设 GridID(一个 4 字节的数字)将在系统中唯一标识各个网格。
合理的网格大小应该如何确定?
网格的大小可以设定为我们希望查询的距离,因为我们也希望减少网格的数量。如果网格的大小等于我们希望查询的距离,那么我们只需要在包含给定位置的网格及其周围的 8 个相邻网格内进行搜索。由于我们的网格大小是固定的(静态定义的),我们可以轻松找到任何位置(纬度、经度)所在的网格编号以及它的相邻网格。
在数据库中,我们可以将 GridID 与每个地点一起存储,并为其建立索引,以提高查询速度。
select * from Places where Latitude between X-D and X+D and Longitude between Y-D and Y+D and GridID in (GridID, GridID1, GridID2, ..., GridID8)这样,我们的查询效率将大大提高。
是否应该将索引存储在内存中?
将索引存储在内存中会提高服务的性能。我们可以使用哈希表来存储索引,其中 key 是网格编号,value 是该网格内的地点列表。
存储索引需要多少内存?
假设我们的搜索半径是 10 英里,地球的总面积约为 2 亿平方英里,那么我们将拥有 2000 万个网格。
每个网格的 GridID 需要 4 字节,而 LocationID 需要 8 字节。因此,仅存储索引(忽略哈希表的开销)将需要大约 4GB 的内存:
(4 * 20M) + (8 * 500M) ~= 4 GB密集区域的查询问题
然而,对于某些网格来说,这种方法可能会运行较慢,因为地点在网格中的分布并不均匀。某些区域可能地点密集,而另一些区域则稀疏。
如何优化?
如果我们能够动态调整网格大小,在一个网格内有大量地点时,我们可以将其细分成更小的网格。
这种方法的挑战包括:
- 如何将这些网格映射到具体的地理位置?
- 如何有效地找到某个网格的所有相邻网格?
c. 动态大小网格 (Dynamic size grids)
假设我们不希望每个网格中有超过 500 个地点,这样可以提高查询速度。因此,每当一个网格达到这个限制时,我们就将其拆分成四个相同大小的网格,并将地点分配到这些新网格中。这意味着像旧金山这样的密集区域将有许多网格,而像太平洋这样的稀疏区域则会有大网格,地点仅分布在海岸线周围。
这种信息可以使用什么数据结构来存储?
一个每个节点有四个子节点的树可以满足我们的需求。每个节点表示一个网格,并包含该网格内所有地点的信息。如果一个节点的地点数达到 500 个,我们将把它拆分为四个子节点,并将地点分配给它们。以此类推,所有的叶子节点将代表无法进一步拆分的网格,因此叶子节点将保留地点的列表。这种每个节点最多有四个子节点的树结构被称为 四叉树 (QuadTree)。
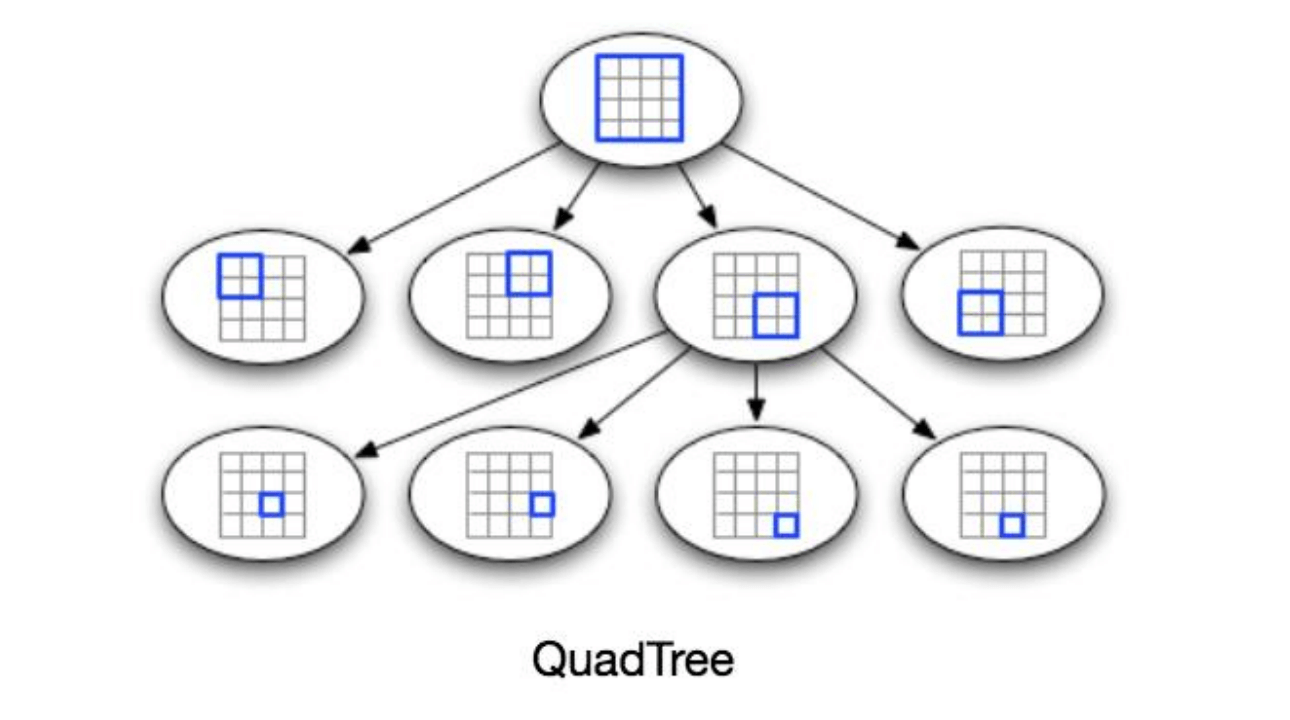
如何构建四叉树?
我们将从一个节点开始,该节点代表整个世界的一个网格。由于它包含超过 500 个地点,我们将将其拆分为四个节点,并将地点分配给它们。我们将继续对每个子节点重复此过程,直到没有任何节点包含超过 500 个地点为止。
如何查找某个位置对应的网格?
我们将从根节点开始,向下查找,直到找到所需的节点/网格。在每一步,我们将检查当前访问的节点是否有子节点。如果有子节点,我们将移动到包含所需位置的子节点并重复此过程。如果该节点没有子节点,那么我们就找到了所需的节点。
如何找到某个网格的相邻网格?
由于只有叶子节点包含地点列表,我们可以将所有叶子节点连接成双向链表。这样,我们就可以在相邻的叶子节点之间前后遍历,找到我们所需的地点。另一种查找相邻网格的方法是通过父节点。我们可以在每个节点中保持一个指针来访问其父节点,并且每个父节点都有指向其所有子节点的指针,因此我们可以轻松地找到一个节点的兄弟节点。我们可以通过向上遍历父指针,继续扩展搜索以找到相邻网格。
一旦我们找到了附近的 LocationID,我们就可以查询后台数据库以获取这些地点的详细信息。
搜索流程是什么?
首先,我们将找到包含用户位置的节点。如果该节点包含足够的地点,我们将直接返回这些地点。如果不足,我们将继续扩展到相邻节点(通过父指针或双向链表)直到找到所需数量的地点,或者根据最大半径耗尽搜索。
存储四叉树需要多少内存?
对于每个地点,如果我们只缓存 LocationID 和 Lat/Long,那么存储所有地点将需要 12GB 的内存。
24 * 500M => 12 GB由于每个网格最多可以容纳 500 个地点,且我们有 5 亿个地点,我们将拥有多少个网格?
500M / 500 => 1M grids这意味着我们将有 100 万个叶子节点,它们将存储 12GB 的位置信息。一个包含 100 万个叶子节点的四叉树将大约有 三分之一 的内部节点,每个内部节点将有 4 个指针(指向它的子节点)。如果每个指针是 8 字节,那么我们存储所有内部节点所需的内存为:
1M * 1/3 * 4 * 8 = 10 MB因此,存储整个四叉树所需的总内存为 12.01GB,这在现代服务器上是可以轻松容纳的。
如何向系统中插入一个新地点?
每当用户添加新地点时,我们需要将其插入到数据库和四叉树中。如果四叉树存储在同一台服务器上,添加新地点是容易的;但如果四叉树分布在不同的服务器上,我们需要先找到新地点所属的网格/服务器,然后将其添加进去(这一过程将在下一节中讨论)。
7. 数据分区
如果我们有大量的地点,以至于我们的索引无法放入单台机器的内存怎么办?考虑到每年 20% 的增长,我们未来可能会达到服务器的内存限制。此外,假如一台服务器无法处理所需的读取流量呢?为了解决这些问题,我们必须对四叉树进行分区!
我们在这里探讨两种解决方案(这两种分区方案也可以应用于数据库):
a. 基于区域的分片 (Sharding based on regions)
我们可以根据区域(如邮政编码)将地点划分为多个区域,每个区域的地点存储在固定的节点上。为了存储一个地点,我们会通过其区域找到服务器,查询附近地点时,我们也会询问包含用户位置的区域服务器。
这种方法有以下几个问题:
如果某个区域变得热点怎么办?
如果某个区域的查询量激增,负责该区域的服务器会受到很大的查询压力,从而导致性能下降,影响服务的响应速度。随着时间推移,某些区域可能会比其他区域存储更多的地点。
因此,随着区域的增长,保持地点的均匀分布变得非常困难。
为了解决这些问题,我们可以重新划分数据,或者使用 一致性哈希 来平衡负载。
b. 基于 LocationID 的分片 (Sharding based on LocationID)
我们的哈希函数将每个 LocationID 映射到一个服务器,在该服务器上存储这个地点。在构建四叉树时,我们将遍历所有地点并计算每个 LocationID 的哈希值,从而确定应该存储在那个服务器上。
查询附近地点时,我们需要查询所有的服务器,每个服务器会返回一组附近的地点。一个中央服务器会将这些结果汇总并返回给用户。
我们会在不同分区上有不同的四叉树结构吗?
是的,这种情况可能会发生,因为我们无法保证所有分区中的每个网格包含相同数量的地点。然而,我们会确保所有服务器大致存储相同数量的地点。这种不同的四叉树结构不会造成任何问题,因为我们会在所有分区上查询所有相邻网格的地点。
本章的剩余部分假设我们已基于 LocationID 对数据进行了分区。
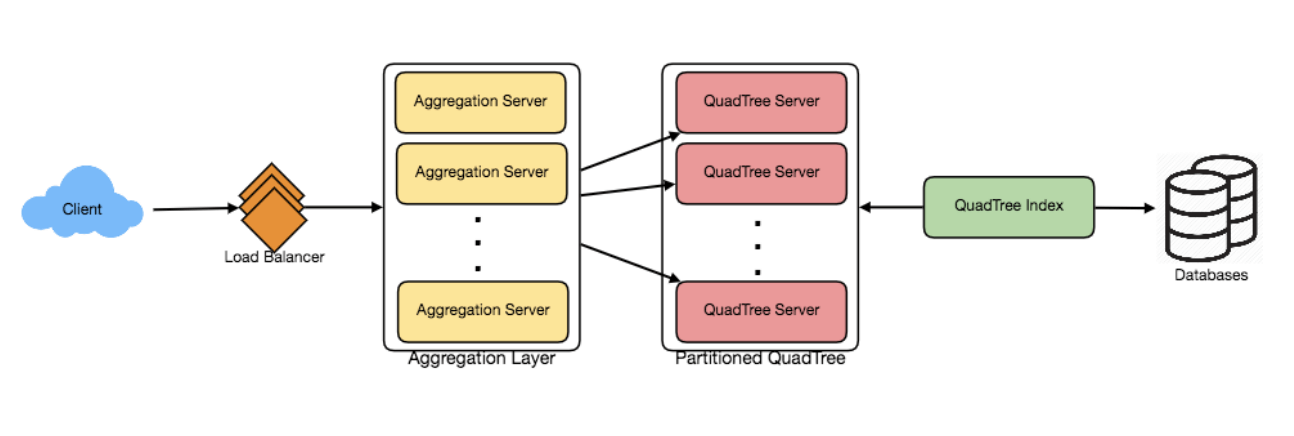
8. 复制与故障容忍
为了应对数据分区的挑战,我们可以通过复制四叉树服务器来分散读取流量。每个四叉树服务器可以采用主从架构,副本(从服务器)只处理读取流量,所有写入流量先发送到主服务器,然后再应用到从服务器。副本可能无法立刻获取最近插入的地点(会有几毫秒的延迟),但这通常是可以接受的。
如果四叉树服务器崩溃怎么办?
我们可以为每个服务器配置一个备用副本。如果主服务器崩溃,备用副本可以在故障转移后接管并继续服务。主服务器和副本将保持相同的四叉树结构。
如果主服务器和副本同时崩溃怎么办?
此时,我们需要分配一台新的服务器,并在该服务器上重建相同的四叉树。问题是,我们怎么知道该服务器上保存了哪些地点?一种笨重的解决方法是遍历整个数据库,使用我们的哈希函数过滤 LocationID,找出应该存储在该服务器上的所有地点。但这种方法效率低下且慢;同时,在服务器重建期间,我们无法为用户提供查询服务,因此将错失一些用户应该看到的地点。
如何高效地检索地点与四叉树服务器的映射?
我们需要构建一个反向索引,将所有地点映射到它们的四叉树服务器。可以创建一个单独的四叉树索引服务器来存储这些信息。我们会构建一个哈希映射,其中“键”是四叉树服务器的编号,“值”是一个哈希集合,包含所有存储在该四叉树服务器上的地点。每个地点需要存储 LocationID 和 Lat/Long 信息,以便信息服务器能够根据这些信息构建它们的四叉树。
注意:我们将地点的数据存储在哈希集合中,这样可以快速地添加/删除地点。因此,当四叉树服务器需要重建时,它可以直接向四叉树索引服务器查询需要存储的所有地点。这个方法会非常高效。我们还应该为四叉树索引服务器配置一个副本,以确保故障容忍。如果四叉树索引服务器崩溃,它可以通过遍历数据库重新构建其索引。
9. 缓存
为了处理热地点(高查询频率的地点),我们可以在数据库前面引入缓存。可以使用像 Memcache 这样的现成解决方案,将所有热门地点的数据存储在缓存中。应用服务器在访问后端数据库之前,可以快速检查缓存是否已经存储了该地点。根据客户端的使用模式,我们可以调整需要多少个缓存服务器。对于缓存驱逐策略,最近最少使用(LRU) 看起来适合我们的系统。
10. 负载均衡
我们可以在系统中的两个位置添加负载均衡层:
- 在 客户端与应用服务器 之间。
- 在 应用服务器与后端服务器 之间。
初步时,我们可以采用简单的 轮询(Round Robin) 方法,它会将所有传入的请求均等地分发给后端服务器。这个负载均衡方法实现简单,不会引入过多开销。它的另一个好处是,如果某个服务器崩溃,负载均衡器会将其从轮询中移除,停止发送请求。
但是,轮询法有一个问题:它不会考虑服务器的负载。如果某台服务器过载或者变慢,负载均衡器仍然会将请求发送到该服务器。因此,我们需要一个更智能的负载均衡解决方案,它定期查询后端服务器的负载情况,并根据负载情况调整流量分配。
11. 排序
如果我们不仅仅按照距离对搜索结果进行排序,还想按流行度或相关性排序,如何处理呢?
如何在给定半径内返回最受欢迎的地点?
假设我们跟踪每个地点的总体流行度,可以用一个聚合数值表示该地点的流行度,比如,地点的平均星级评分(由用户给出)。我们将在数据库和四叉树中存储这个流行度值。在搜索给定半径内的前 100 个地点时,我们可以让每个四叉树分区返回流行度最高的前 100 个地点,然后由聚合服务器汇总这些结果,最终确定所有分区中前 100 个流行地点。
如何修改四叉树中地点的流行度?
请记住,我们的系统并未设计为频繁更新地点数据。对于这种设计,更新地点的流行度可能会非常消耗资源,并影响搜索请求和系统吞吐量。假设我们预期地点的流行度变化不会在几小时内反映到系统中,我们可以决定在系统负载较低的时段(例如,每天一次或两次)进行更新。
接下来的章节《设计Uber后台》将详细讨论四叉树的动态更新问题。