设计一个类似 TinyURL 的 URL 缩短服务
让我们设计一个类似 TinyURL 的 URL 缩短服务。该服务将提供指向长 URL 的短别名。
类似服务:bit.ly、goo.gl、qlink.me 等
难度等级:简单
1. 为什么需要 URL 缩短?
URL 缩短用于为长 URL 创建更短的别名。我们称这些缩短的别名为“短链接”。用户访问这些短链接时会被重定向到原始 URL。短链接在显示、打印、消息传递或推文时能节省大量空间。此外,用户输入较短的 URL 时出错的几率较小。
例如,如果我们通过 TinyURL 缩短此页面链接:
https://www.educative.io/collection/page/5668639101419520/5649050225344512/5668600916475904/
我们将得到:
http://tinyurl.com/jlg8zpc
缩短后的 URL 大小仅为原始 URL 的三分之一。URL 缩短还用于跨设备优化链接、跟踪个别链接以分析受众和活动表现,并隐藏关联的原始 URL。
如果您以前没有使用过 tinyurl.com,请尝试创建一个新的缩短 URL,并花些时间浏览其服务提供的各种选项。这将有助于您理解本章内容。
2. 系统的需求和目标
💡 在面试开始时,您应始终明确需求。确保提出问题,以确定面试官设想的系统范围。
我们的 URL 缩短系统应满足以下需求:
功能性需求:
- 给定一个 URL,系统应生成一个更短且唯一的别名,称为短链接。
- 当用户访问短链接时,系统应将其重定向到原始链接。
- 用户可以选择为其 URL 选择自定义短链接。
- 链接将在标准的默认时间段后过期,用户可以指定过期时间。
非功能性需求:
- 系统应高度可用,因为如果服务中断,所有 URL 重定向将会失败。
- URL 重定向应实时发生,且延迟最小化。
- 短链接应不可猜测(不可预测)。
扩展需求:
- 分析功能,例如记录重定向的次数。
- 其他服务可以通过 REST API 访问我们的服务。
3. 容量估算和约束
我们的系统将是一个读取频繁的系统,与新的 URL 缩短请求相比,重定向请求会更多。假设读取与写入的比例为 100:1。
流量估算: 假设每月有 5 亿个新的 URL 缩短请求,在 100:1 的读写比例下,我们可以预期在同一期间内会有 500 亿次重定向请求:
100 * 5 亿 = 500 亿
每秒查询数 (QPS) 估算:
新 URL 缩短请求的每秒查询数为: 5 亿 / (30 天 * 24 小时 * 3600 秒) ≈ 200 个 URL/秒
考虑到 100:1 的读写比例,URL 重定向每秒的查询数为:
100 * 200 URLs/秒 = 20,000 次/秒
存储估算: 假设我们将每个 URL 缩短请求(及其关联的缩短链接)存储 5 年。由于我们预计每月有 5 亿个新 URL,因此我们预计存储的对象总数为 300 亿个:
5 亿 * 5 年 * 12 个月 = 300 亿
假设每个存储对象大约为 500 字节(只是一个粗略估算,稍后会深入探讨),我们将需要 15TB 的总存储:
300 亿 * 500 字节 = 15 TB
带宽估算:
- 对于写请求,由于我们预计每秒有 200 个新 URL,因此服务的总传入数据为 100KB/秒:
200 * 500 字节 = 100 KB/秒 - 对于读请求,由于每秒预计有约 2 万个 URL 重定向,服务的总传出数据为 10MB/秒:
20,000 * 500 字节 = ~10 MB/秒
内存估算:
如果我们希望缓存一些被频繁访问的热门 URL,那么需要多少内存来存储它们?如果遵循 80-20 法则,即 20% 的 URL 生成 80% 的流量,我们将缓存这 20% 的热门 URL。
由于我们每秒有 2 万次请求,每天约 17 亿次请求:
20,000 * 3600 秒 * 24 小时 = ~17 亿次请求
为了缓存其中的 20%,我们需要 170GB 内存:
0.2 * 17 亿 * 500 字节 = ~170GB
需要注意的是,由于会有大量重复的请求(对同一 URL),因此实际的内存使用量会低于 170GB。
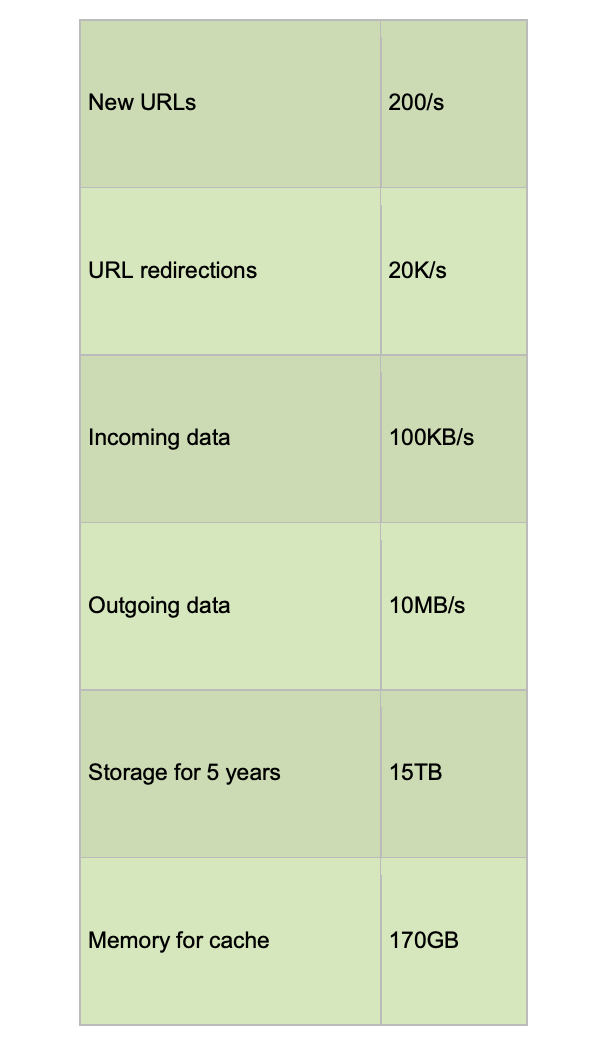
高层估算总结: 假设每月有 5 亿个新 URL,以及 100:1 的读写比例,以下是该服务的高层估算汇总:
4. 系统 APIs
💡 一旦确认了需求,定义系统 API 是一个好习惯。这可以明确系统的预期功能。
我们可以使用 SOAP 或 REST API 来公开服务功能。以下是创建和删除 URL 的 API 定义:
createURL(api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)
参数:
api_dev_key(string): 注册账户的 API 开发密钥,用于根据分配的配额限制用户请求频率。original_url(string): 要缩短的原始 URL。custom_alias(string): 可选的 URL 自定义键。user_name(string): 可选,用于编码的用户名。expire_date(string): 可选,缩短 URL 的过期日期。
返回值: (string)
插入成功返回缩短后的 URL,否则返回错误代码。
deleteURL(api_key, url_key)
删除请求时使用 url_key(表示要删除的缩短 URL)。成功删除返回 "URL Removed"。
如何检测和防止滥用?
恶意用户可能通过消耗所有 URL 键来使系统无法正常运行。为防止滥用,我们可以通过 api_dev_key 限制用户。每个 api_dev_key 可以被限定在一定时间内创建和重定向 URL 的数量(每个开发密钥的时间周期可以不同)。
5. 数据库设计
💡 在面试初期定义数据库模式有助于理解各组件之间的数据流,并为后续的数据分区提供指导。
关于将要存储的数据的几点观察:
- 我们需要存储数十亿条记录。
- 每个存储对象都很小(小于 1KB)。
- 记录之间没有关系——除了记录哪个用户创建了 URL。
- 我们的服务读取频繁。
数据库模式:
我们需要两个表:一个用于存储 URL 映射信息,另一个用于存储创建短链接的用户数据。

应选择哪种数据库?
由于预计将存储数十亿行记录,且无需对象之间的关系,NoSQL 键值存储(如 DynamoDB、Cassandra 或 Riak)是更合适的选择。使用 NoSQL 数据库还更易于扩展。关于 SQL 与 NoSQL 的更多信息,请参见相关资料。
6. 基本系统设计与算法
我们要解决的问题是:如何为给定的 URL 生成一个短小且唯一的密钥。
在第 1 节的 TinyURL 示例中,短链接为“http://tinyurl.com/jlg8zpc”。URL 最后的六个字符是我们需要生成的短密钥。我们将探讨两种解决方案:
a. 编码实际 URL (Encoding actual URL)
我们可以对给定的 URL 计算一个唯一哈希(如 MD5 或 SHA256)。然后将该哈希编码显示。编码可以是 base36([a-z, 0-9])或 base62([A-Z, a-z, 0-9]),如果加入 ‘-’ 和 ‘.’ 则可以使用 base64 编码。一个合理的问题是,短密钥应该多长?6、8 或 10 个字符。
- 使用 base64 编码,6 个字符的密钥会有 64^6 ≈ 687 亿个可能的字符串。
- 使用 base64 编码,8 个字符的密钥会有 64^8 ≈ 281 万亿个可能的字符串。
有了 687 亿个唯一字符串,我们假设六个字符的密钥对我们的系统足够。
如果我们使用 MD5 算法作为哈希函数,它会生成一个 128 位的哈希值。base64 编码后,生成的字符串长度超过 21 个字符(因为每个 base64 字符编码哈希值的 6 位)。由于我们只需要短密钥中有 8 个字符,那么如何选择密钥呢?我们可以取前 6(或 8)个字符作为密钥。这可能导致密钥重复,在这种情况下,可以从编码字符串中选择其他字符或替换某些字符。
该方案的主要问题:
- 如果多个用户输入相同的 URL,他们会得到相同的短链接,这不可接受。
- 如果 URL 的部分内容经过 URL 编码会怎样?
例如,http://www.educative.io/distributed.php?id=design和http://www.educative.io/distributed.php%3Fid%3Ddesign除了 URL 编码外是相同的。
问题解决方法:
我们可以为每个输入的 URL 添加一个递增的序列号以使其唯一化,然后生成其哈希。我们无需在数据库中存储此序列号。该方法的问题是序列号的不断增长,可能会导致溢出,并且对服务性能有一定影响。
另一种解决方案是将用户 ID(应为唯一)附加到输入 URL 上。然而,如果用户未登录,则需要让用户选择一个唯一性密钥。即便如此,如果存在冲突,我们需要继续生成密钥直到得到一个唯一的。
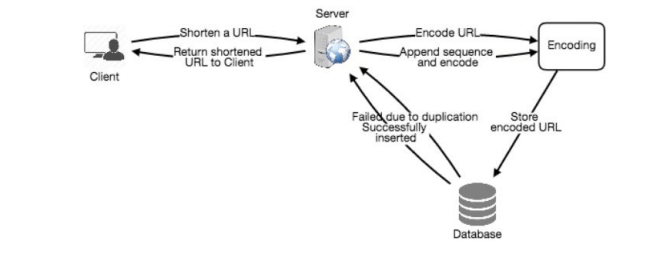
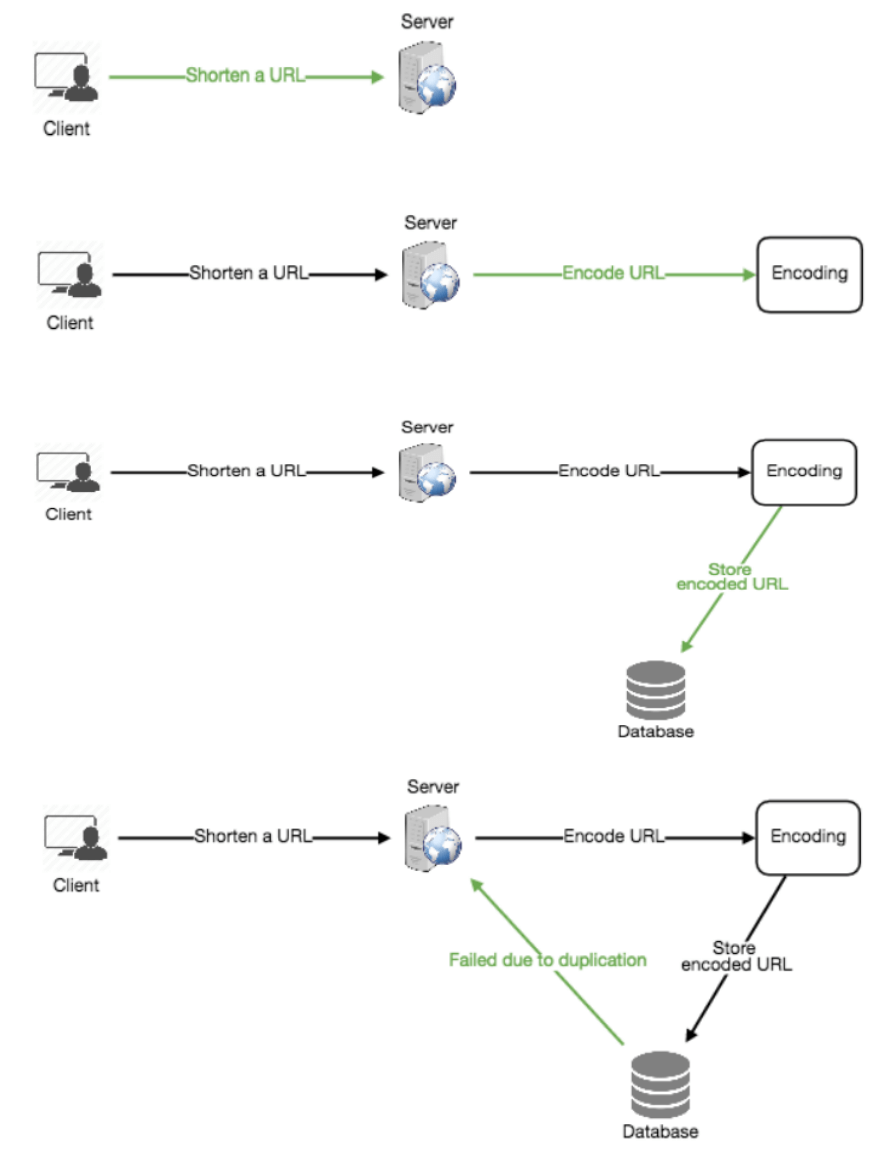
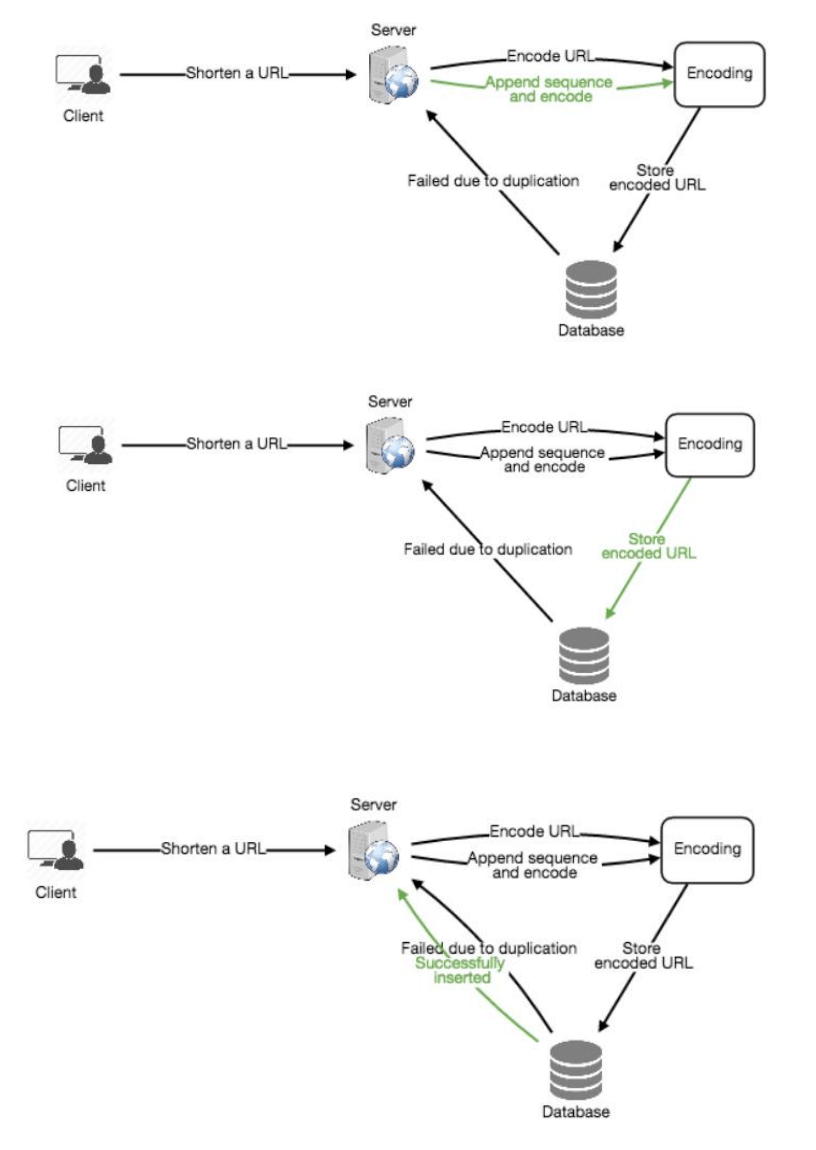
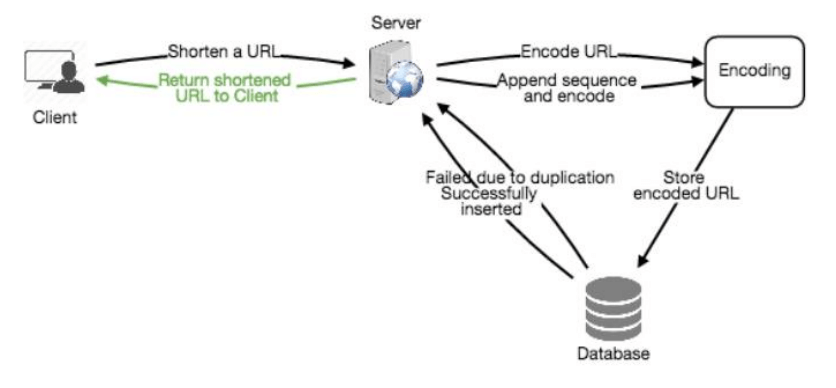
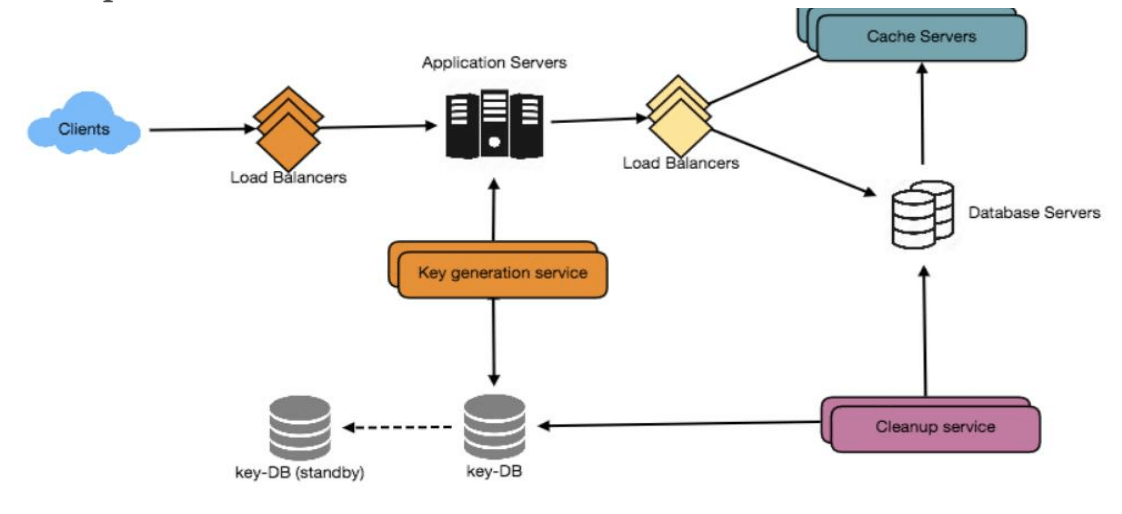
b. 离线生成密钥 (Generating keys offline)
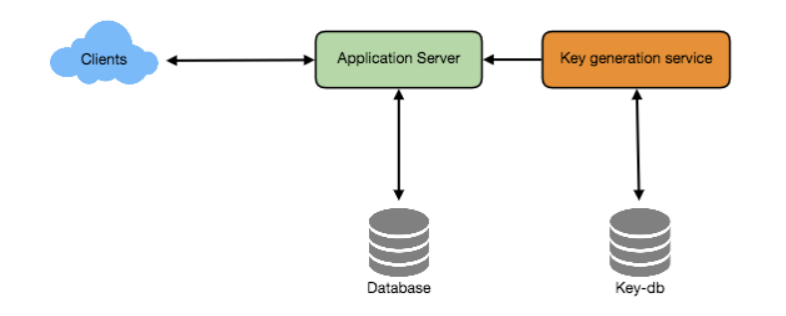
我们可以设置一个独立的密钥生成服务(KGS),提前生成随机的六字符字符串并将其存储在一个数据库中(称为 key-DB)。在需要缩短 URL 时,直接从已经生成的密钥中取出一个并使用。这种方法简单快速,不仅不需要对 URL 进行编码,还可以避免重复和冲突。KGS 将确保插入 key-DB 的密钥是唯一的。
并发问题
一旦密钥被使用,数据库中应将其标记为已使用,以确保不会再次使用。如果有多个服务器同时读取密钥,可能会出现两个或多个服务器尝试从数据库读取相同密钥的情况。如何解决这个并发问题?
服务器可以使用 KGS 读取并标记数据库中的密钥。KGS 可使用两个表存储密钥:一个用于未使用的密钥,另一个用于所有已使用的密钥。一旦 KGS 将密钥分配给某个服务器,它就会将该密钥移到已使用密钥表中。KGS 可以在内存中保留一些密钥,以便在服务器需要时快速提供。
为简化流程,KGS 可以将加载到内存的密钥直接移到已使用表中,从而保证每个服务器获得唯一的密钥。如果 KGS 在分配所有加载的密钥之前崩溃,我们将丢失这些密钥,但考虑到庞大的密钥数量,这是可以接受的。
KGS 如何防止给多个服务器分配相同密钥?
为防止多个服务器获得相同密钥,KGS 在删除密钥并将其分配给服务器之前,需对存储密钥的数据结构进行同步(或加锁)。
key-DB 的大小
使用 base64 编码,可以生成 687 亿个唯一的六字符密钥。如果每个字符需要 1 字节来存储,则我们可以存储这些密钥的总大小为:
6(每个密钥的字符数)× 687 亿(唯一密钥数)= 412 GB。
KGS 是否是单点故障?
是的。为了解决这个问题,可以设置 KGS 的备用副本。当主服务器故障时,备用服务器可以接管密钥的生成和分配。
每个应用服务器可以缓存一些 key-DB 中的密钥吗?
可以,这可以加速服务。不过如果应用服务器在使用完所有密钥前崩溃,则会丢失这些密钥。考虑到我们拥有 687 亿个唯一的六字符密钥,这种损失是可以接受的。
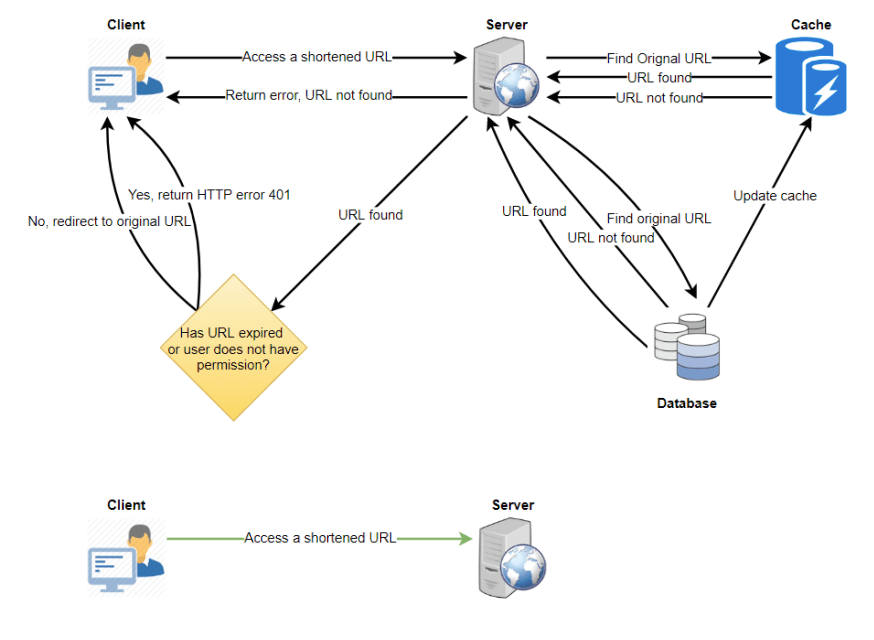
如何进行密钥查找?
我们可以在数据库或键值存储中查找密钥以获得完整的 URL。如果存在,则返回 HTTP 302 重定向状态,并在请求的 "Location" 字段中传递存储的 URL。如果密钥不存在,返回 HTTP 404 状态或将用户重定向到首页。
是否应限制自定义别名的长度?
我们的服务支持自定义别名。用户可以选择任何喜欢的密钥,但提供自定义别名并非强制。然而,为保持 URL 数据库的一致性,限制自定义别名的长度是合理的。假设用户的自定义密钥最多可包含 16 个字符(反映在上面的数据库模式中)。
7. 数据分区与复制
为了扩展数据库,需要对其进行分区,以便可以存储数十亿条 URL 的信息。我们需要设计一个分区方案,将数据分散存储在不同的数据库服务器上。
a. 基于范围的分区 (Range Based Partitioning)
可以根据 URL 或其哈希值的首字母,将 URL 存储到不同的分区中。例如,将所有以字母 “A” 开头的 URL 存储在一个分区,以字母 “B” 开头的 URL 存储在另一个分区,以此类推。这种方法称为基于范围的分区。还可以将某些不常见的字母组合成一个数据库分区。通过使用静态分区方案,可以在需要时以可预测的方式存储和查找文件。
这种方法的主要问题是可能导致服务器负载不平衡。例如,如果决定将所有以字母 “E” 开头的 URL 存储在一个数据库分区中,但后来发现有太多 URL 以字母 “E” 开头,这会导致单一分区超负荷。
b. 基于哈希的分区 (Hash-Based Partitioning)
在这种方案中,对存储的对象进行哈希操作,并基于哈希结果来决定使用哪个分区。对于本系统,可以对 URL 的 “key” 或实际 URL 进行哈希,以确定数据对象的存储分区。
我们的哈希函数会将 URL 随机分布到不同的分区中(例如,将任何键映射到一个 1 到 256 的数值范围),这个数值将表示对象存储的分区。
此方法可能仍会导致某些分区负载过高的问题,可以通过 一致性哈希 来解决。
8. 缓存
可以缓存经常被访问的 URL。可以使用一些现成的解决方案,例如 Memcache,用于存储完整的 URL 及其对应的哈希值。应用服务器在访问后端存储之前可以快速检查缓存是否包含所需的 URL。
缓存容量需求
可以从每日流量的 20% 开始缓存,并根据用户使用情况调整所需的缓存服务器数量。如前所述,缓存每日流量的 20% 需要 170GB 的内存。现代服务器可以拥有 256GB 的内存,可以轻松地在一台服务器上装入所有缓存。或者,可以使用几台较小的服务器来存储这些热点 URL。
选择合适的缓存淘汰策略
当缓存满时,如果需要用较新或更热的 URL 替换旧 URL,应如何选择?对于该系统,最近最少使用(LRU)策略是一个合理的选择。在此策略下,会首先丢弃最近未被访问的 URL。可以使用 Linked Hash Map 或类似的数据结构来存储 URL 和哈希值,同时跟踪最近访问的 URL。
为进一步提高效率,可以复制缓存服务器以分散负载。
如何更新缓存副本?
当出现缓存未命中时,服务器会访问后端数据库。每次发生这种情况时,更新缓存并将新条目传递给所有缓存副本。每个副本可以通过添加新条目来更新其缓存。如果副本已经拥有该条目,则可以忽略该操作。
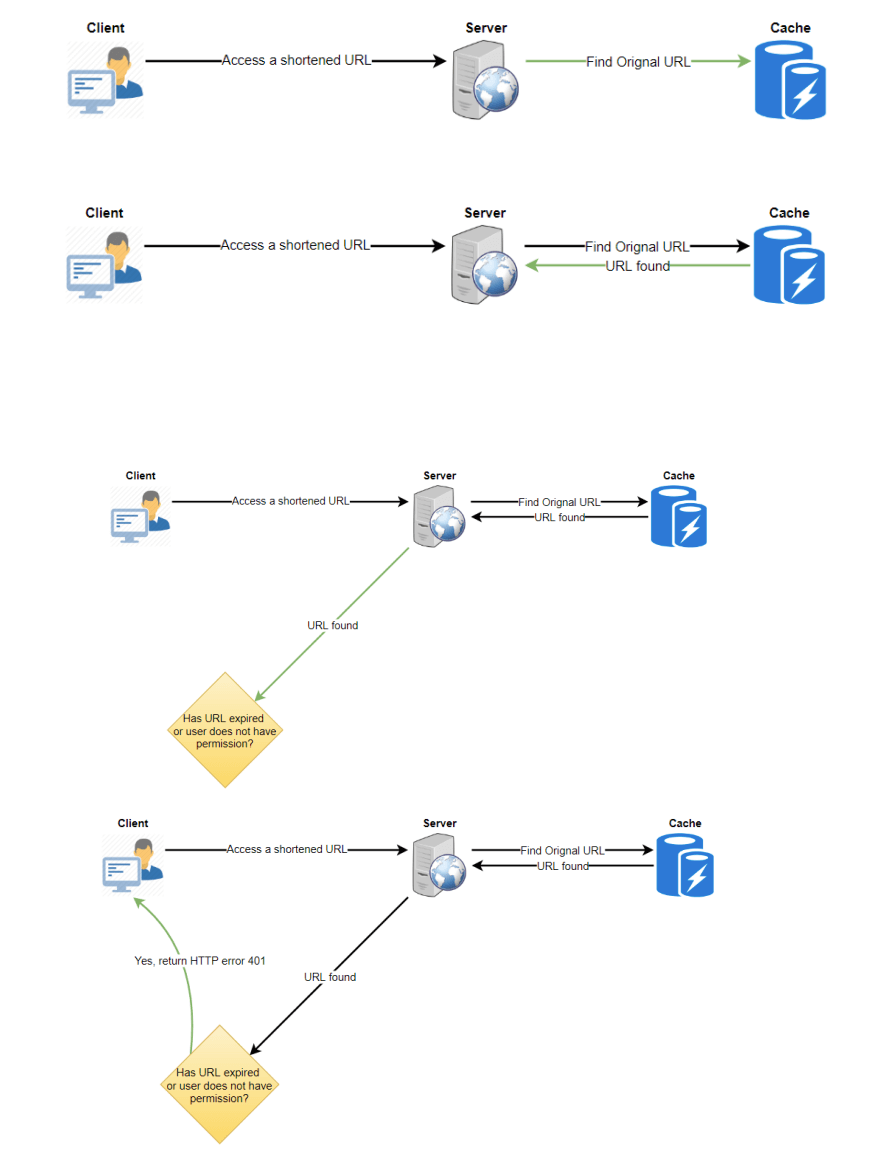
9. 负载均衡器 (LB)
在系统中,可以在以下三个地方添加负载均衡层:
- 客户端与应用服务器之间
- 应用服务器与数据库服务器之间
- 应用服务器与缓存服务器之间
起初,可以采用简单的轮询 (Round Robin) 方法,将请求平均分配到后端服务器。这种负载均衡策略简单易实现,并且不会带来额外的开销。另一个优势是,如果某台服务器宕机,负载均衡器会将其从循环中移除,停止向其发送请求。
轮询法的问题
轮询方法的一个问题是没有考虑到服务器负载。如果服务器过载或处理速度较慢,负载均衡器仍会继续发送新请求到该服务器。为了解决这个问题,可以使用更智能的负载均衡方案,使负载均衡器定期查询后端服务器的负载情况,并根据负载动态调整流量分配。
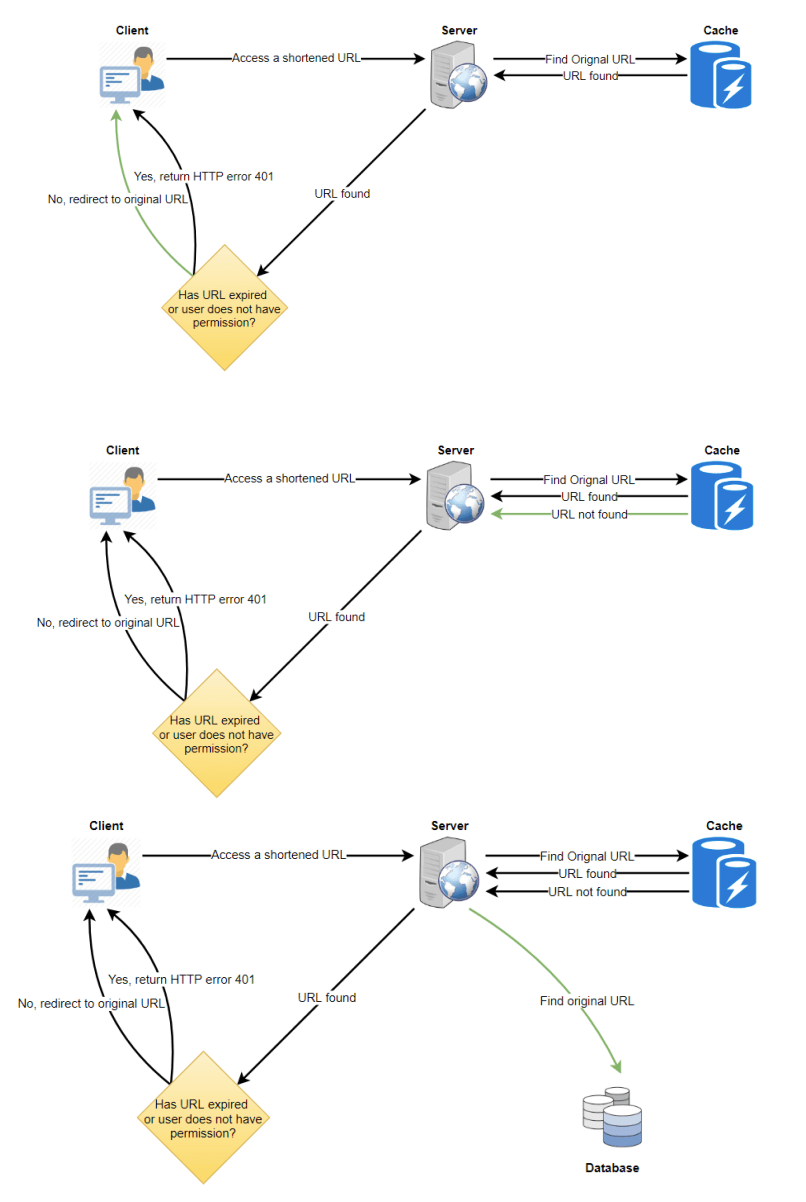
10. 清除或数据库清理 (Purging or DB cleanup)
URL 是否应永久保留?若用户指定的到期时间已过,系统应如何处理该链接?
如果选择主动查找并删除已过期的链接,会对数据库产生很大压力。相反,可以缓慢删除过期链接,采用惰性清理机制。此机制确保只有过期链接会被删除,尽管某些过期链接可能存在时间更长,但不会再返回给用户。
- 当用户尝试访问过期链接时,可以删除该链接并向用户返回错误信息。
- 可以设置一个单独的清理服务,定期从存储和缓存中删除过期链接。该服务应尽量轻量化,并可安排在用户流量较低的时段运行。
- 设定默认过期时间,例如每个链接默认两年到期。
- 回收已删除的过期链接的键,放回
key-DB以便重新使用。 - 是否删除长时间未访问的链接(如六个月未访问)?这会较为复杂。由于存储成本不断降低,可以选择永久保留这些链接。
11. 监控 (Telemetry)
如何追踪短链接的使用情况,例如短链接被访问的次数、用户位置等?如果将这些统计信息存储在每个访问都会更新的数据库行中,当某个热门链接遭遇大量并发请求时,会发生什么情况?
值得追踪的一些统计信息:
- 访问者的国家
- 访问的日期和时间
- 引导点击的网页
- 访问页面所用的浏览器或平台
对于高并发情况下的统计信息更新,可能会导致数据库性能问题。解决这一问题的方法可以包括:
- 异步更新:在后台记录访问数据而不阻塞主操作,这样可以减少对数据库的直接写入压力。可以将统计信息存储在内存中(如使用缓存),并定期批量写入数据库。
- 使用时序数据库:例如,InfluxDB或Prometheus等专门设计用于高频数据写入的数据库,这些数据库能有效处理大量统计信息的记录。
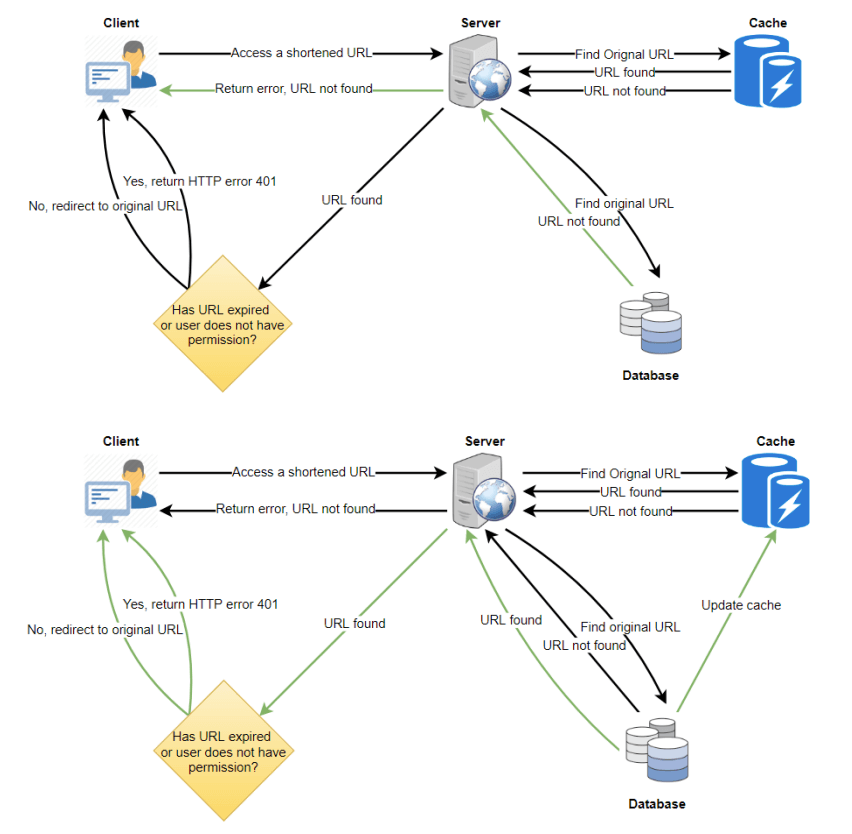
12. 安全性和权限 (Security and Permissions)
用户是否可以创建私有链接或允许特定用户访问某个链接?
可以通过将每个链接的权限级别(公共/私有)存储在数据库中来实现此功能。此外,可以创建一个单独的表格,用于存储具有访问特定链接权限的用户ID。如果某个用户没有权限访问某个链接,当其尝试访问时,系统可以返回HTTP 401错误。
- 数据库设计:
- 使用一个NoSQL宽列数据库(如Cassandra),存储权限的表的键可以是“Hash”或KGS生成的“key”。
- 列将存储具有访问该链接权限的用户ID。
这样的设计确保了访问控制的灵活性和效率,允许不同级别的访问管理。