设计 Twitter
我们来设计一个类似 Twitter 的社交网络服务。用户可以发布推文、关注他人并收藏推文。
难度级别:中等
1. 什么是 Twitter?
Twitter 是一个在线社交网络服务,用户可以发布和阅读长度为 140 字符的短消息,称为“推文”。注册用户可以发布和阅读推文,未注册用户只能阅读推文。用户可以通过网站、短信或移动应用访问 Twitter。
2. 系统的需求与目标
我们将设计一个简化版的 Twitter,包含以下需求:
功能性需求
- 用户可以发布新推文。
- 用户可以关注其他用户。
- 用户可以将推文标记为收藏。
- 系统应能创建并显示用户时间线,包含用户关注的所有人的热门推文。
- 推文可以包含照片和视频。
非功能性需求
- 系统需要高度可用。
- 时间线生成的可接受延迟为 200 毫秒。
- 在可用性优先的情况下,系统的强一致性要求可以适当降低;如果用户暂时看不到某条推文,可以接受。
拓展需求
- 推文搜索。
- 回复推文。
- 热门话题——当前热点话题/搜索。
- @用户标签。
- 推文通知。
- 关注建议。
- “时刻”功能。
3. 容量估算与限制
假设我们有10亿用户,总共有2亿日活跃用户(DAU)。另外假设每天有1亿条新推文,每个用户平均关注200人。
每天的点赞次数?
如果每个用户平均每天点赞五次,那么我们将有:
2亿用户 * 5 次点赞 => 10亿次点赞
系统每天会产生多少次推文查看?
假设用户平均每天访问时间线两次,并访问其他五个人的页面。在每个页面上,用户看到20条推文,那么系统每天将产生280亿次推文查看:
2亿日活跃用户 * ((2 + 5) * 20条推文) => 280亿次/天
存储估算
假设每条推文有140个字符,存储字符时不进行压缩,每个字符需要2字节。假设每条推文需要30字节存储元数据(如ID、时间戳、用户ID等)。我们需要的总存储量为:
1亿条 * (280 + 30)字节 => 30GB/天
我们五年的存储需求会是多少?
用户数据、关注、点赞的数据需求是多少?我们将留给练习解答。
并非所有推文都包含媒体内容,假设平均每五条推文包含一张照片,每十条推文包含一个视频。再假设每张照片平均大小为200KB,每个视频大小为2MB。那么每天新增的媒体内容为24TB:
(1亿/5 张照片 * 200KB) + (1亿/10 个视频 * 2MB) ≈ 24TB/天
带宽估算
由于每天的总输入量为24TB,这相当于290MB/秒。
记住我们每天有280亿次推文查看。我们必须显示每条推文的照片(如果有照片),假设用户在时间线上每三次观看中有一次观看视频。因此,总输出量将是:
(280亿 * 280字节) / 86400秒 文本 => 93MB/秒
+ (280亿/5 * 200KB ) / 86400秒 照片 => 13GB/秒
+ (280亿/10/3 * 2MB ) / 86400秒 视频 => 22GB/秒
总计约为 35GB/秒4. 系统API
💡 一旦我们确定了需求,定义系统API是个好主意。这将明确系统的预期功能。
我们可以使用SOAP或REST API来提供服务的功能。以下是发布新推文的API定义示例:
tweet(api_dev_key, tweet_data, tweet_location, user_location, media_ids, maximum_results_to_return)
参数:
api_dev_key(string): 已注册账号的API开发者密钥。此密钥用于根据分配的配额限制用户。tweet_data(string): 推文文本,通常最多为140个字符。tweet_location(string): 此推文涉及的可选位置(经度、纬度)。user_location(string): 添加推文的用户的可选位置(经度、纬度)。media_ids(number[]): 可选的媒体ID列表,用于关联到推文。(所有媒体如照片、视频等需单独上传)。
返回值: (string)
成功发布将返回访问该推文的URL,否则会返回相应的HTTP错误。
5. 高层系统设计
我们需要一个系统,能够高效地存储所有新增的推文(100M/86400秒 ≈ 每秒1150条推文)并读取已有推文(28B/86400秒 ≈ 每秒325K条推文)。从需求可以看出,这是一个以读操作为主的系统。
在高层架构上,我们需要多个应用服务器来处理所有请求,并在其前端设置负载均衡器以分配流量。在后端,我们需要一个高效的数据库,既能存储所有新增的推文,又能支持大量的读取。同时,我们需要一些文件存储空间来存储照片和视频。
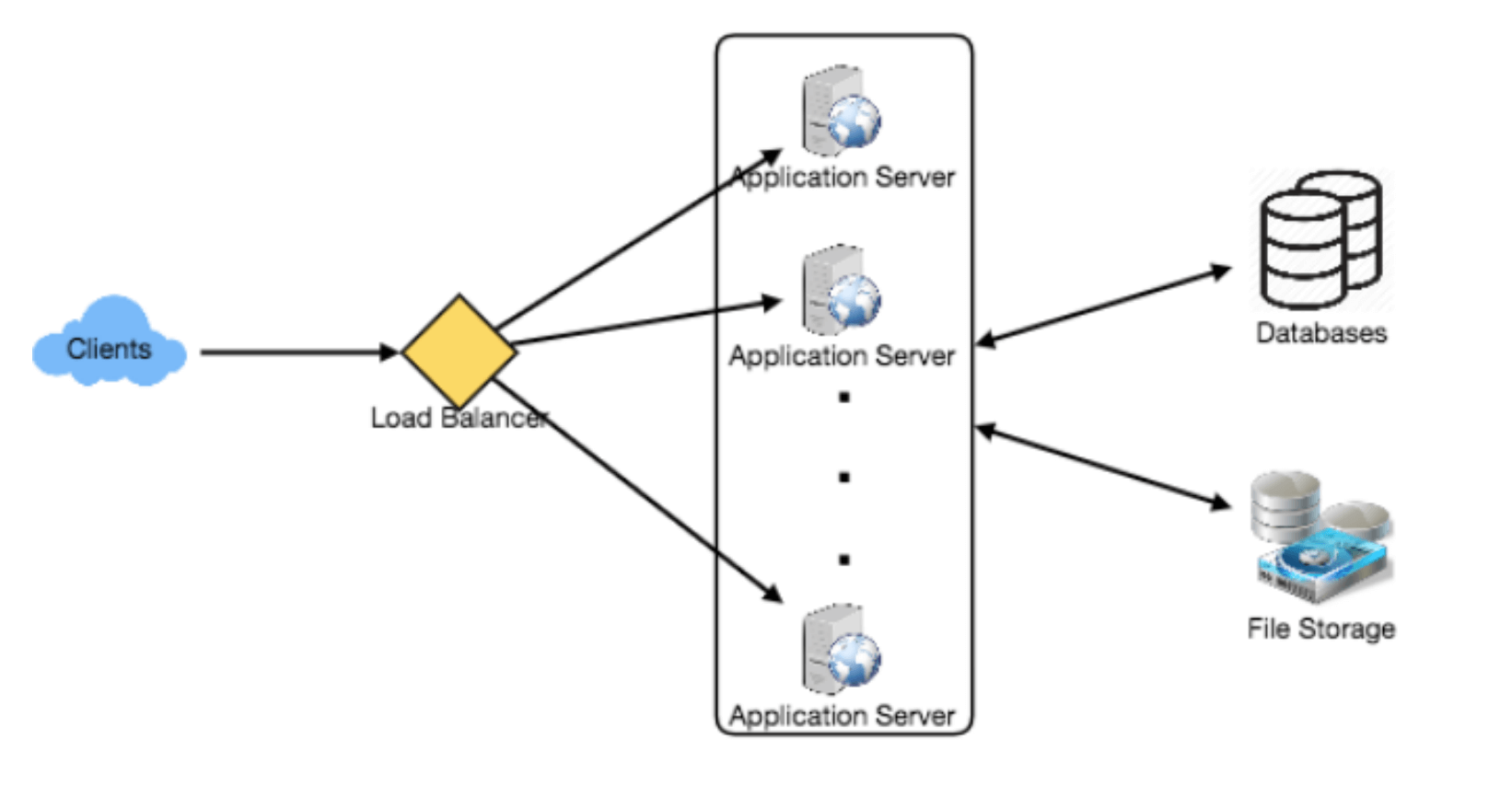
虽然预期的日写入负载为1亿条推文、读取负载为280亿条推文,但平均来看,系统每秒大约会接收1160条新推文和325K次读取请求。然而,这些流量在一天内的分布并不均匀,在高峰期,我们至少需要应对数千次写入请求和约100万次读取请求。设计系统架构时需考虑到这一点。
6. 数据库架构
我们需要存储关于用户、他们的推文、他们收藏的推文以及他们关注的人等数据。
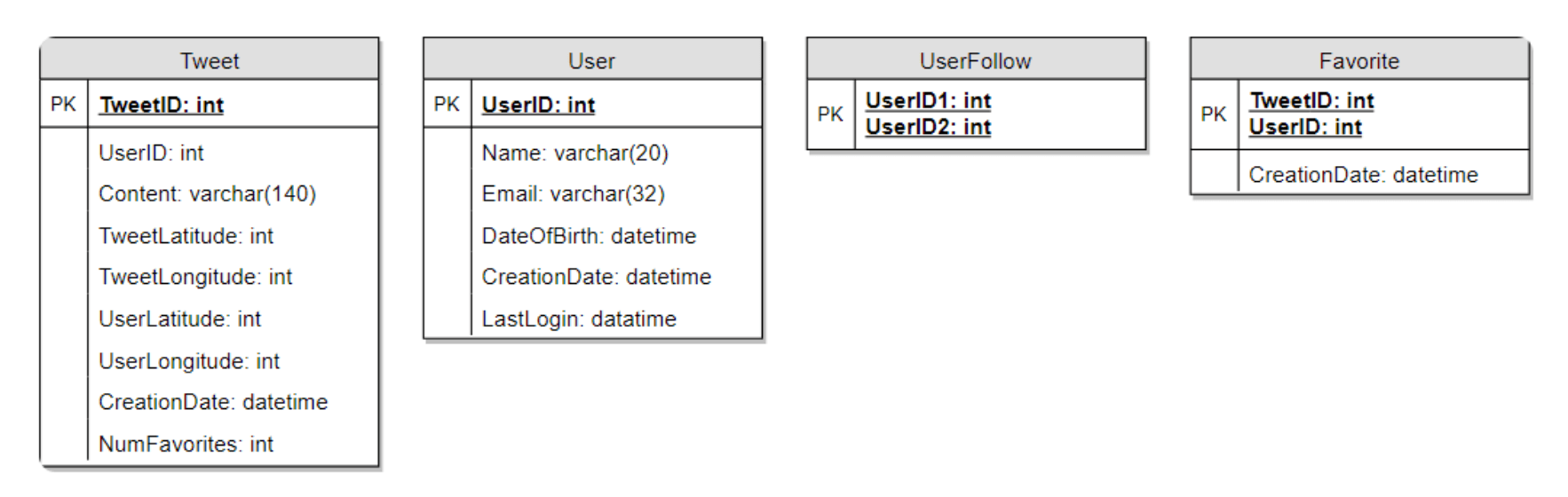
关于选择SQL还是NoSQL数据库来存储上述架构,请参见《设计Instagram》中的“数据库架构”部分。
7. 数据分片
由于我们每天有大量的新推文,而且读负载也非常高,我们需要将数据分布到多个机器上,以便高效地进行读写。我们有很多选项可以对数据进行分片,下面逐一介绍:
基于UserID的分片:我们可以尝试将一个用户的所有数据存储在一台服务器上。在存储时,我们可以将UserID传递给哈希函数,该函数将用户映射到一个数据库服务器,所有该用户的推文、收藏、关注等数据都存储在该服务器上。在查询用户的推文、关注或收藏时,我们可以通过哈希函数查询到该用户的数据存储位置,然后从中读取数据。该方法有几个问题:
- 如果一个用户变得非常热门怎么办?可能会有大量的查询请求集中在该用户所在的服务器上。这种高负载将影响服务的性能。
- 随着时间推移,一些用户的推文或关注人数可能远多于其他用户,导致数据分布不均。保持用户数据的均匀分布是非常困难的。
为了解决这些问题,我们可以重新分区/重新分配数据,或使用一致性哈希。
基于TweetID的分片:我们的哈希函数将每个TweetID映射到一个随机服务器,在该服务器上存储推文。要搜索推文,我们需要查询所有服务器,每个服务器会返回一组推文。一个集中式服务器将聚合这些结果并返回给用户。让我们来看一个生成时间线的例子,以下是系统生成用户时间线时需要执行的步骤:
- 应用服务器找到用户关注的所有人。
- 应用服务器将查询发送到所有数据库服务器,查找这些人的推文。
- 每个数据库服务器会找到该用户的推文,按时间顺序排序并返回最新的推文。
- 应用服务器将合并所有结果并再次排序,最终返回给用户最顶部的推文。
这种方法解决了“热门用户”问题,但与基于UserID的分片不同,我们需要查询所有数据库分区来查找某个用户的推文,这可能导致更高的延迟。
我们还可以通过在数据库服务器前引入缓存来进一步提升性能,将热门推文缓存起来。
基于推文创建时间的分片:根据推文创建时间进行分片,可以使我们快速获取所有的最新推文,而且只需要查询一小部分服务器。然而,这种方法的问题在于流量负载的不均衡。例如,在写入时,所有新的推文都会写入到同一台服务器,其他服务器则处于空闲状态。同样,在读取时,持有最新数据的服务器会承受比存储旧数据的服务器更高的负载。
结合基于TweetID和推文创建时间的分片:如果我们不单独存储推文创建时间,而是通过TweetID来反映创建时间,我们可以同时享有两者的优点。这样,我们可以快速找到最新的推文。为了实现这一点,我们必须使每个TweetID在系统中都是唯一的,并且每个TweetID都应该包含时间戳。
我们可以使用纪元时间(epoch time)来实现这一点。假设我们的TweetID将由两部分组成:第一部分表示纪元秒数,第二部分是一个自动递增的序列号。因此,生成一个新的TweetID时,我们可以取当前的纪元时间,并在其后附加一个递增的数字。然后我们可以根据这个TweetID来确定数据所在的分片,并将其存储在那里。
TweetID的大小:假设我们的纪元时间从今天开始,我们需要多少位来存储未来50年的秒数?
86400 sec/day * 365 (days a year) * 50 (years) => 1.6B

我们需要31个位来存储这个数字。由于我们平均每秒钟有1150条新推文,我们可以分配17个位来存储自增序列;这样我们的TweetID将是48个位长。因此,每秒钟我们可以存储(2^17 => 130K)条新推文。我们可以每秒重置自增序列。为了提高容错性和性能,我们可以设置两台数据库服务器来生成自增键,一台生成偶数编号的键,另一台生成奇数编号的键。
如果我们假设当前的纪元秒数是“1483228800”,那么我们的TweetID将是这样的: 78
1483228800 000001
1483228800 000002
1483228800 000003
1483228800 000004
……
如果我们将TweetID设置为64位(8字节)长,我们可以轻松地存储未来100年的推文,并且能够存储到毫秒级别的精度。
在上述方法中,我们仍然需要查询所有服务器来生成时间线,但我们的读写速度将显著提高。
- 由于我们没有创建时间的二级索引,这将减少我们的写入延迟。
- 在读取时,我们不需要根据创建时间进行过滤,因为我们的主键中已经包含了纪元时间。
8. 缓存
我们可以为数据库服务器引入缓存,用于缓存热推文和用户数据。我们可以使用现成的解决方案,如Memcache,来存储整个推文对象。在数据库查询之前,应用服务器可以快速检查缓存中是否有所需的推文。根据客户端的使用模式,我们可以确定需要多少缓存服务器。
哪种缓存替换策略最适合我们的需求?当缓存满了,我们希望用更新的/更热门的推文替换现有推文时,应该如何选择?最少最近使用(LRU)策略对于我们的系统来说是一个合理的选择。在这种策略下,我们首先丢弃最近最少被查看的推文。
如何实现更智能的缓存?如果我们遵循80-20规则,即20%的推文生成80%的读取流量,这意味着某些推文非常受欢迎,大多数人都在查看这些推文。这就要求我们尝试缓存每个分片中20%的日常读取量。
如果我们缓存最新的数据会怎样?我们的服务可以从这种方式中受益。假设80%的用户仅查看过去三天的推文,我们可以尝试缓存过去三天的所有推文。假设我们有专用的缓存服务器,缓存所有用户过去三天的推文。如上所述,我们每天会产生1亿条新推文,或30GB的新数据(不包括图片和视频)。如果我们想要存储过去三天的所有推文,我们需要的内存不足100GB。这个数据完全可以存储在一台服务器上,但我们应将其复制到多台服务器上,以分担所有读取流量,从而减轻缓存服务器的负载。因此,每当我们生成用户的时间线时,可以向缓存服务器询问是否有该用户的所有最新推文。如果有,我们可以直接从缓存中返回所有数据。如果缓存中没有足够的推文,我们就需要查询后端服务器以获取数据。在类似的设计中,我们也可以尝试缓存过去三天的照片和视频。
我们的缓存将像一个哈希表,其中“键”是“OwnerID”,“值”是一个双向链表,包含该用户过去三天的所有推文。由于我们希望优先获取最新的数据,因此我们可以始终将新推文插入链表的头部,这样所有较旧的推文就会靠近链表的尾部。因此,我们可以从尾部删除推文,以为更新的推文腾出空间。
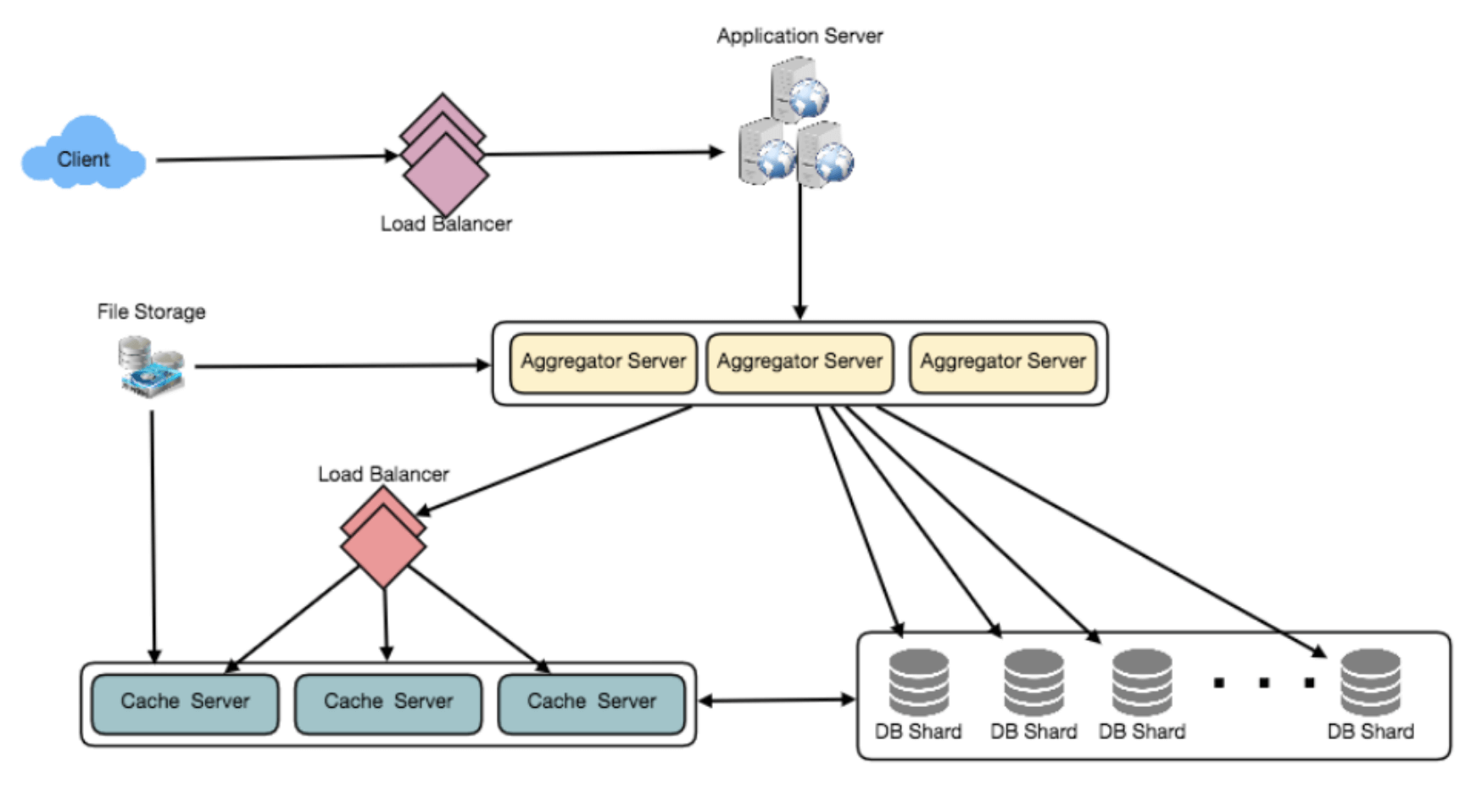
9. 时间线生成
关于时间线生成的详细讨论,请参阅《设计Facebook的新闻推送》。
10. 复制和容错
由于我们的系统是读密集型的,我们可以为每个数据库分区设置多个辅助数据库服务器。辅助服务器将仅用于读取流量。所有写入操作将首先发送到主服务器,然后复制到辅助服务器。该方案还提供了容错能力,因为每当主服务器出现故障时,我们可以切换到辅助服务器。
11. 负载均衡
我们可以在系统的三个地方添加负载均衡层:1)客户端与应用服务器之间;2)应用服务器与数据库复制服务器之间;3)聚合服务器与缓存服务器之间。最初可以采用简单的轮询(Round Robin)方法,均匀地将传入请求分配到各个服务器。这种负载均衡实现简单,不会带来额外开销。另一个好处是,如果某台服务器宕机,负载均衡将把它从轮询中移除,并停止发送流量到这台服务器。轮询负载均衡的一个问题是,它不会考虑服务器的负载。如果某台服务器过载或响应缓慢,负载均衡仍然会继续向其发送请求。为了解决这个问题,可以使用更智能的负载均衡解决方案,定期查询后端服务器的负载,并根据负载情况调整流量。
12. 监控
监控系统的能力至关重要。我们应该不断收集数据,实时了解系统的运行情况。我们可以收集以下指标/计数器来了解服务的性能:
- 每天/每秒的新推文数量,每日的最高峰值是多少?
- 时间线传递统计信息,我们的服务每天/每秒传递多少推文。
- 用户刷新时间线时的平均延迟。
通过监控这些计数器,我们将能发现是否需要更多的复制、负载均衡或缓存。
13. 扩展需求
我们如何提供信息流?获取某人关注的所有人的最新推文,并根据时间合并/排序它们。使用分页来获取/显示推文。仅获取某人关注的所有人中的前N条推文。这个N值将取决于客户端的视口,因为在移动端我们显示的推文比Web客户端少。我们还可以缓存下一个前N条推文来加速加载。
或者,我们可以预生成信息流以提高效率;详情请参阅《设计Instagram》中的“排名与时间线生成”部分。
转发:对于数据库中的每个推文对象,我们可以存储原始推文的ID,而不存储转发对象的内容。
趋势话题:我们可以缓存过去N秒内最频繁出现的标签或搜索查询,并在每M秒后更新它们。我们可以根据推文、搜索查询、转发或点赞的频率来排名趋势话题。对于被更多人看到的话题,我们可以给予更高的权重。
如何推荐关注的人?如何给出建议?这个功能将提高用户的参与度。我们可以建议某人关注的朋友,也可以向下查找两三层,找到名人来做推荐。我们可以优先推荐拥有更多粉丝的人。
由于每次只能做少量推荐,可以使用机器学习(ML)进行推荐的重新排序和优先级调整。ML信号可以包括最近增加关注者的人、共同关注者(如果另一个人也关注了该用户)、共同位置或兴趣等。
时刻:获取过去1到2小时内各大网站的热门新闻,找到相关推文,对其进行优先排序和分类(新闻、支持、金融、娱乐等),使用机器学习(监督学习或聚类)。然后,我们可以将这些文章作为趋势话题展示在时刻中。
搜索:搜索包括推文的索引、排名和检索。类似的解决方案将在我们的下一个问题“设计Twitter搜索”中讨论。