一致性哈希
分布式哈希表(Distributed Hash Table,DHT)是分布式可扩展系统中的核心组件之一。哈希表需要一个键(key)、一个值(value)和一个哈希函数(hash function),其中哈希函数用于将键映射到存储该值的位置:
index = hash_function(key)假设我们正在设计一个分布式缓存系统,给定 n 个缓存服务器,一个直观的哈希函数是 key % n。这种方法简单且常见,但存在两个主要缺陷:
不可水平扩展(Not Horizontally Scalable):每当系统新增缓存服务器时,所有现有的映射都会被打乱。如果缓存系统包含大量数据,维护将变得极其困难。实际上,安排停机时间来更新所有缓存映射在实践中也非常棘手。
可能导致负载不均衡(May Not Be Load Balanced):特别是对于非均匀分布的数据而言,
key % n并不能保证负载均衡。在实际应用中,数据往往不会均匀分布,这可能导致某些缓存服务器负载过高,成为“热点”,而其他服务器则几乎空闲。
在这种情况下,一致性哈希是一种优化缓存系统的有效方法。
什么是一致性哈希?
一致性哈希(Consistent Hashing)是一种在分布式缓存系统和分布式哈希表(DHTs)中非常有用的策略。它可以在集群中分布数据,同时最小化节点增删时的重组工作量,从而使缓存系统更易扩展和缩减。
在一致性哈希中,当哈希表调整大小(例如添加新的缓存服务器)时,只有 k/n 个键需要重新映射,其中 k 是总键数,n 是服务器总数。而在使用取模(mod)作为哈希函数的缓存系统中,所有键都需要重新映射。
一致性哈希尽量保证对象映射到相同的主机。当某个主机被移除时,该主机上的对象会被其他主机接管;当新增主机时,它只会从少数几个主机中分担部分数据,而不会影响其他主机的存储。
一致性哈希的工作原理
与典型的哈希函数类似,一致性哈希将键映射到一个整数。例如,假设哈希函数的输出范围是 [0, 256),可以想象这些整数沿着一个环形排列,使值在边界处循环。
一致性哈希的具体步骤如下:
- 服务器映射:将缓存服务器的标识(如 IP 地址)通过哈希函数映射到整数范围内。
- 键映射到服务器:
- 使用哈希函数计算键的哈希值,得到一个整数。
- 在哈希环上顺时针移动,直到找到第一个遇到的缓存服务器。
- 该缓存服务器即存储该键的服务器。例如,在下图示例中:
key1映射到缓存服务器Akey2映射到缓存服务器C
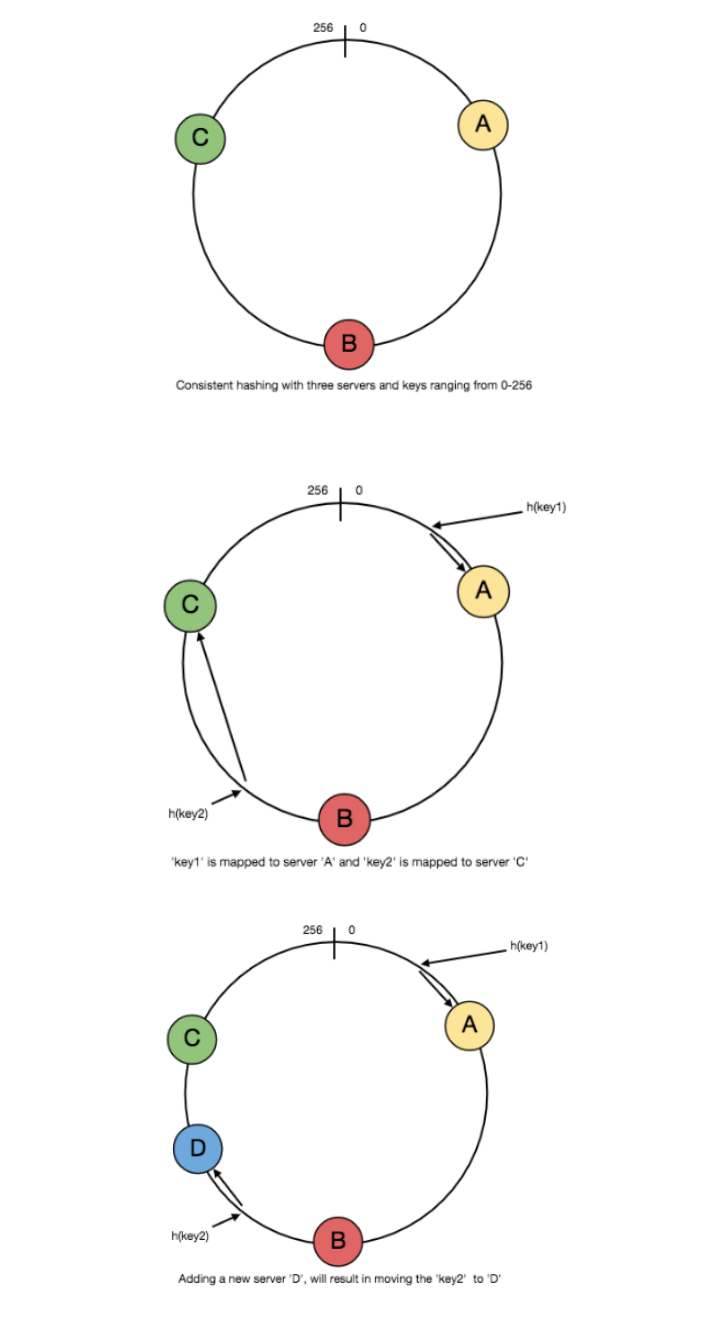
当添加新服务器(例如 D)时,原本映射到 C 的部分键会被重新分配到 D,而其他键不会受到影响。
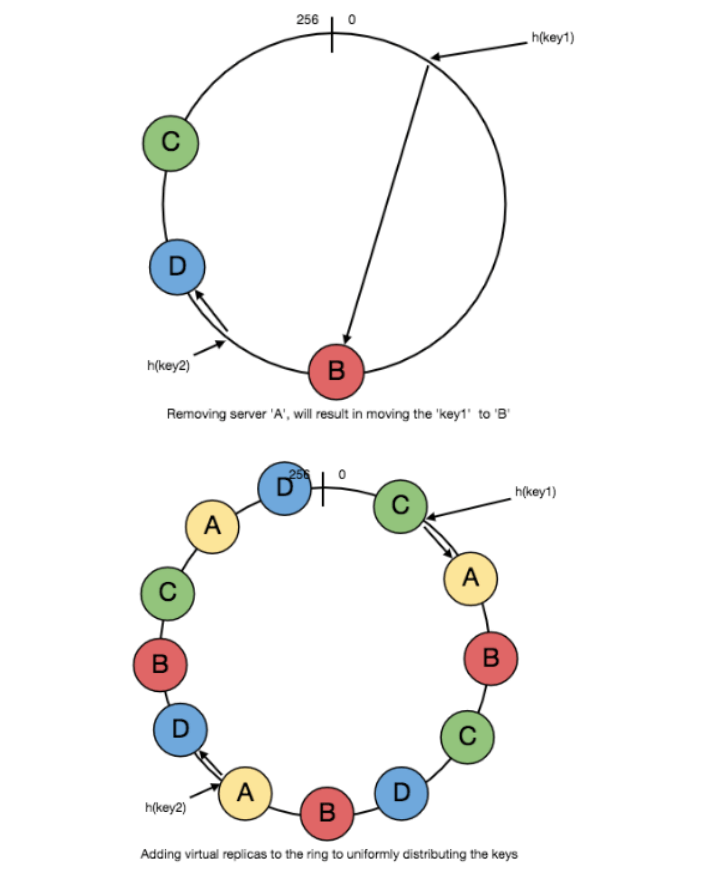
当移除缓存服务器(或服务器故障,例如 A 失效)时,原本映射到 A 的所有键都会重新映射到 B,并且只有这些键需要迁移到 B,其他键不会受到影响。
负载均衡
正如前面讨论的,实际数据的分布本质上是随机的,因此可能不会均匀,导致某些缓存服务器的键过多,而其他服务器的键较少,造成负载不均衡。
为了解决这个问题,我们可以为每个缓存服务器添加虚拟副本(Virtual Replicas)。与其将每个服务器映射到哈希环上的单个点,我们可以将其映射到多个点,即创建多个副本。这样,每个缓存服务器就会管理哈希环上的多个区域,从而分担负载。
如果哈希函数的分布足够均匀,那么随着副本数量的增加,键的分布也会更加均衡。