设计 Facebook 的新闻推送
让我们设计 Facebook 的新闻推送,该功能将包含用户关注的所有人和页面的帖子、照片、视频以及状态更新。
类似服务:Twitter 新闻推送、Instagram 新闻推送、Quora 新闻推送
难度等级:困难
1. Facebook 的新闻源(Newsfeed)是什么?
新闻源是 Facebook 主页中间不断更新的故事列表,其中包含用户关注的好友、页面和群组发布的状态更新、照片、视频、链接、应用活动及“点赞”等内容。换句话说,新闻源是一个完整、可滚动的动态流,展示了用户及其好友的生活记录,包括照片、视频、位置、状态更新等。
对于任何社交媒体平台(如 Twitter、Instagram 或 Facebook),都需要一个新闻源系统来展示好友和关注者的动态更新。
2. 系统的需求和目标
我们设计一个 Facebook 的新闻源系统,要求如下:
功能性需求
- 新闻源基于用户关注的好友、页面和群组的动态生成。
- 用户可能拥有大量好友,并关注众多页面和群组。
- 新闻源内容可能包含图片、视频或纯文本。
- 需要支持实时向所有活跃用户的新闻源中追加新动态。
非功能性需求
- 系统应能够实时生成用户的新闻源,用户端的最大可接受延迟为 2 秒。
- 一条动态应在 5 秒内出现在用户的新闻源中(假设用户在此时请求新的新闻源)。
3. 容量估算与约束
假设每位用户平均拥有 300 个好友,并关注 200 个页面。
流量估算
假设每日活跃用户数为 3 亿,每位用户平均每天请求新闻源 5 次,这将产生 15 亿次新闻源请求/天,即 每秒约 17,500 次请求。
存储估算
假设我们需要在每位用户的新闻源中保留 500 条动态,并且每条动态平均占用 1KB 存储空间。
- 每位用户的新闻源数据量 ≈ 500KB
- 需要存储所有活跃用户的数据 ≈ 150TB
- 如果每台服务器可存储 100GB 数据,则需要 约 1500 台服务器 来缓存所有活跃用户的前 500 条动态。
4. 系统 API
💡 在确定需求后,定义系统 API 是一个不错的做法,它可以明确系统的预期行为。
我们可以使用 SOAP 或 REST API 来暴露服务的功能。以下是获取新闻推送(newsfeed)API 的定义:
getUserFeed(api_dev_key, user_id, since_id, count, max_id, exclude_replies)参数:
- api_dev_key (string):API 开发者密钥,注册用户可使用该密钥进行身份验证,并用于基于配额限制用户请求频率等操作。
- user_id (number):需要获取新闻推送的用户 ID。
- since_id (number, 可选):返回 ID 大于指定值(即比该 ID 更新)的结果。
- count (number, 可选):指定返回的推送条目数量,单次请求最多可获取 200 条。
- max_id (number, 可选):返回 ID 小于或等于指定值(即比该 ID 旧)的结果。
- exclude_replies (boolean, 可选):如果设置为
true,返回结果中将不会包含回复内容。
返回值:
(JSON) 返回一个 JSON 对象,包含新闻推送条目的列表。
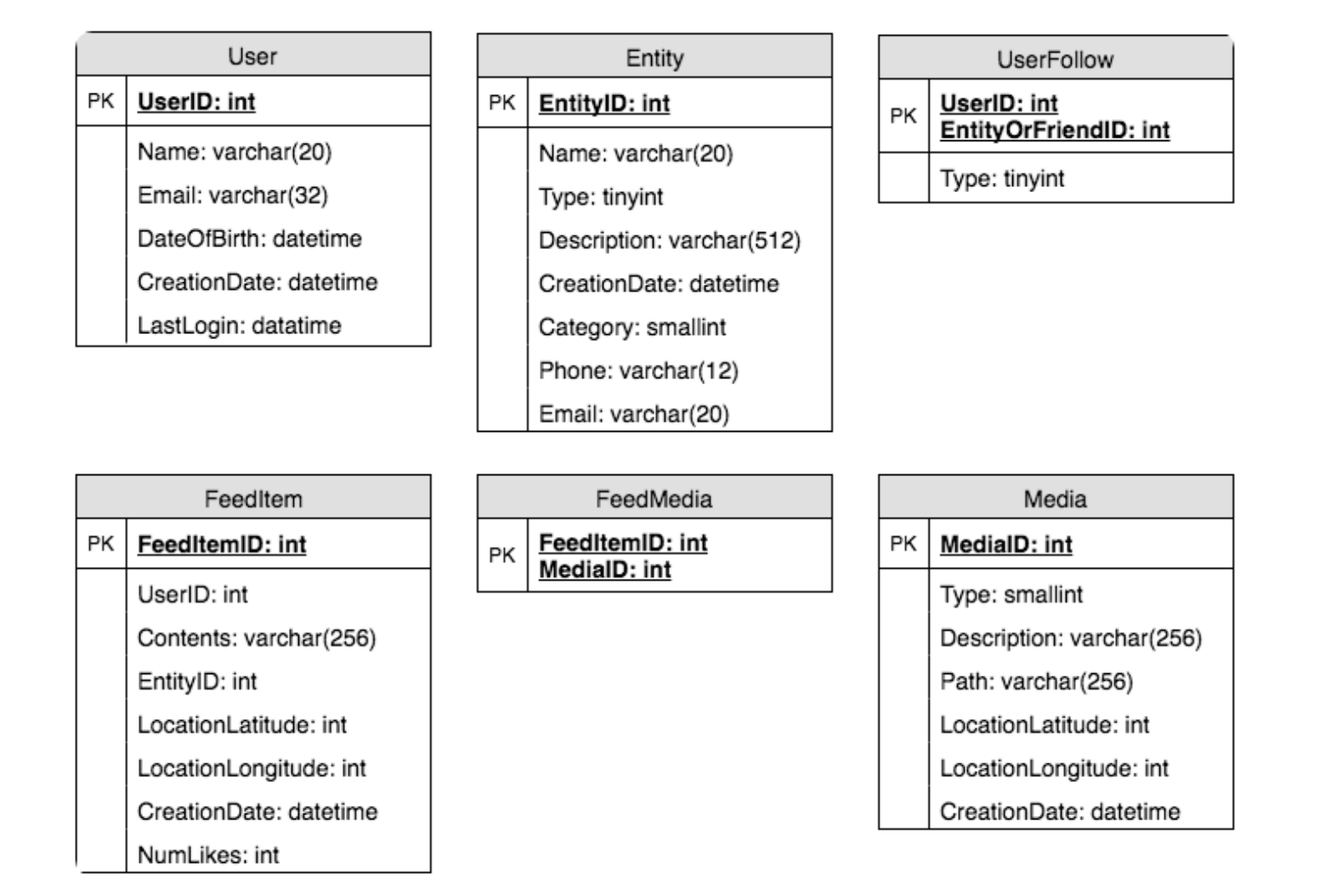
5. 数据库设计
系统包含三个主要对象:用户(User)、实体(Entity,如页面、群组等)和动态项(FeedItem 或 Post)。以下是这些实体之间关系的一些观察:
- 用户可以关注其他实体,也可以与其他用户成为朋友。
- 用户和实体都可以发布动态项(FeedItem),其中可包含文本、图片或视频。
- 每个动态项都包含一个用户 ID(UserID),指向创建该动态的用户。
- 为了简化起见,我们假设只有用户可以创建动态项,尽管在 Facebook 上,页面也可以发布动态。
- 每个动态项还可以包含一个可选的实体 ID(EntityID),指向该动态所属的页面或群组。
如果使用关系型数据库,需要建模两个关系:用户-实体关系(User-Entity relation) 和 动态项-媒体关系(FeedItem-Media relation)。
- 由于每个用户可以与许多用户成为朋友,并关注大量实体,因此可以将这些关系存储在单独的表中。
- 在 UserFollow 表的 Type 列中,标识被关注对象是用户还是实体。
- 类似地,可以创建 FeedMedia 表来存储动态项与媒体的关系。
6. 高层系统设计
从高层来看,这个问题可以分为两个部分:
1. 动态消息生成
新闻动态(Newsfeed)是从用户和实体(页面或群组)的帖子(或动态项)中生成的,用户可以关注这些实体。因此,每当系统收到请求以生成用户(例如 Jane)的新闻动态时,我们将执行以下步骤:
- 获取 Jane 关注的所有用户和实体的 ID。
- 检索这些 ID 对应的最新、最受欢迎且最相关的帖子,这些帖子将作为 Jane 新闻动态的候选内容。
- 根据与 Jane 的相关性对这些帖子进行排序,形成 Jane 当前的新闻动态。
- 将该动态存入缓存,并返回前 N 条(例如 20 条)帖子以供 Jane 展示。
- 在前端,当 Jane 滑到底部时,可以从服务器获取接下来的 20 条帖子,以此类推。
需要注意的是,我们在生成新闻动态后会将其存入缓存。那么,如果 Jane 关注的人发布了新的帖子,该如何处理?如果 Jane 在线,我们需要一个机制对新帖进行排序并添加到她的新闻动态中。我们可以定期(如每 5 分钟)执行上述步骤,以便对新帖子进行排序并添加到她的动态中。随后,Jane 会收到通知,提示她有新的动态可获取。
2. 动态消息推送
每当 Jane 加载新闻动态页面时,她需要向服务器请求并拉取动态项。当她滑到底部后,可以继续从服务器拉取更多数据。对于新帖子,服务器可以选择两种方式:
- 通知 Jane,然后由 Jane 主动拉取新内容。
- 服务器直接推送新帖子到 Jane 的客户端。
我们将在后续详细讨论这两种方案。
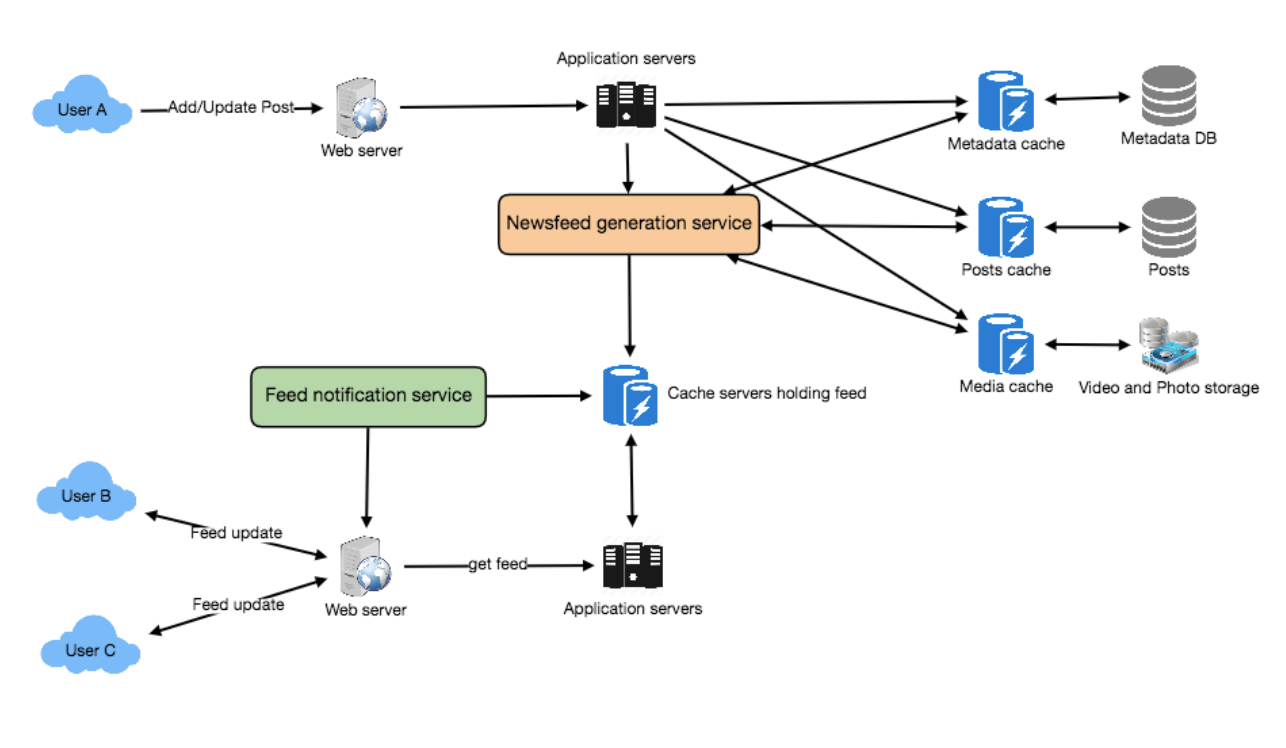
新闻动态服务的高层组件
我们的新闻动态系统主要包含以下组件:
- Web 服务器:用于维护与用户的连接,并在用户和服务器之间传输数据。
- 应用服务器:负责执行存储新帖的工作流,同时用于检索和推送新闻动态给用户。
- 元数据数据库和缓存:用于存储用户、页面和群组的元数据。
- 帖子数据库和缓存:用于存储帖子及其相关元数据。
- 视频和图片存储及缓存:基于 Blob 存储,用于存储帖子中的所有媒体内容。
- 新闻动态生成服务:用于收集和排序所有与用户相关的帖子,生成新闻动态并存入缓存,同时支持接收实时更新,将新帖子添加到用户的时间线中。
- 动态通知服务:用于通知用户有新动态可查看。
下图展示了系统的高层架构,其中用户 B 和 C 关注了用户 A。
7. 详细组件设计
我们来详细讨论系统的各个组件。
a. 动态生成
以新闻动态生成服务为例,假设该服务需要获取 Jane 关注的所有用户和实体的最新帖子,其查询可能如下:
(SELECT FeedItemID FROM FeedItem WHERE UserID in (
SELECT EntityOrFriendID FROM UserFollow WHERE UserID = <current_user_id> and type = 0(user)
))
UNION
(SELECT FeedItemID FROM FeedItem WHERE EntityID in (
SELECT EntityOrFriendID FROM UserFollow WHERE UserID = <current_user_id> and type = 1(entity)
))
ORDER BY CreationDate DESC
LIMIT 100该动态生成服务设计存在的问题:
- 速度极慢:对于关注大量好友/实体的用户,需要对海量帖子进行排序、合并和排名,导致查询速度极慢。
- 高延迟:在用户加载页面时才生成动态,响应速度慢,延迟较高。
- 实时更新的积压:每次状态更新都会触发所有关注者的动态更新,可能导致新闻动态生成服务积压严重。
- 推送负载过高:服务器向用户推送或通知新帖子时,尤其是对于拥有大量关注者的用户或页面,可能会产生极高的负载。
改进方案:预生成动态
为提高效率,我们可以预生成用户的动态并存储在内存中。
离线生成新闻动态
可以使用专门的服务器持续生成用户的新闻动态,并将其存储在内存中。这样,用户请求动态时,不需要即时计算,而是直接从预存的结果中获取。
当服务器需要为某个用户生成动态时,会先查询该用户上次生成动态的时间点,然后从该时间点开始计算新的动态数据。该数据可以存储在哈希表中,**键(Key)**为用户ID,**值(Value)**为如下结构体(STRUCT):
Struct {
LinkedHashMap<FeedItemID, FeedItem> feedItems;
DateTime lastGenerated;
}我们可以使用类似 LinkedHashMap 或 TreeMap 的数据结构来存储 FeedItemID,这样不仅可以快速跳转到任意动态项,还能方便地遍历整个映射。
当用户请求更多动态时,他们可以发送当前新闻动态中最后一个 FeedItemID,然后我们可以在哈希映射中找到该 FeedItemID,并从该位置返回下一批动态数据。
内存中应存储多少条动态?
初始方案是为每个用户存储 500 条动态,但可以根据使用模式调整。例如:
- 如果一页动态包含 20 篇帖子,且大多数用户不会浏览超过 10 页,那么我们可以将存储量减少至 200 条动态。
- 对于希望查看更多动态的用户,可以向后端服务器查询额外的帖子数据。
是否应该为所有用户生成并缓存新闻动态?
并非所有用户都会频繁登录,因此需要优化存储策略:
- LRU 缓存淘汰策略:使用 LRU(Least Recently Used) 缓存机制,移除长时间未访问新闻动态的用户数据,以节省内存。
- 智能预测用户登录模式:分析用户的访问习惯,预测他们活跃的时间段,并在适当时间点预生成新闻动态,例如:
- 用户一天中活跃的时间
- 用户每周访问新闻动态的频率
在接下来的部分,我们将探讨如何优化 实时更新 方案。
b. 动态发布
将帖子推送给所有关注者的过程称为 Fanout(广播)。
- 推送(Push)模式 称为 Fanout-on-write(写时广播)。
- 拉取(Pull)模式 称为 Fanout-on-load(加载时广播)。
我们来探讨不同的动态发布方案。
1. 拉取模式(Pull)——Fanout-on-load
该方法会将所有最新的动态数据存储在内存中,用户需要时可从服务器拉取。客户端可以定期拉取动态,或者手动刷新以获取最新内容。
缺点:
- 延迟问题:新内容不会立即显示,用户必须主动请求才能看到新动态。
- 资源浪费:如果拉取请求没有新数据,服务器会返回空响应,导致资源浪费。
2. 推送模式(Push)——Fanout-on-write
当用户发布新帖子时,服务器会立即将其推送给所有关注者。
优点:
- 取动态时无需遍历好友列表,大大减少 读操作,提高访问效率。
缺点:
- 需要维护一个 长轮询(Long Polling) 连接,以便服务器向客户端发送更新。
- 对于拥有 数百万关注者的明星用户,服务器需要同时向大量用户推送数据,可能造成 巨大负载。
3. 混合模式(Hybrid)
混合方案结合了 写时广播(Fanout-on-write) 和 加载时广播(Fanout-on-load),可以优化性能:
- 针对普通用户:继续使用 推送(Push)模式,确保关注者能及时收到更新。
- 针对明星用户(大量关注者):禁用推送,让关注者自行拉取更新,以减少服务器开销。
- 优化策略:
- 只向 在线好友 推送动态,减少无效推送。
- 结合 推送通知(Push to Notify) 和 拉取获取(Pull to Serve),确保系统既高效又灵活。
请求时返回多少条动态?
每次请求应设置最大返回条数(例如 20 条),但允许客户端根据设备类型(移动端 vs. 桌面端)自行调整请求数量。
是否始终通知用户有新动态?
桌面端 可以开启通知,而 移动端 由于流量成本较高,可以采用 “下拉刷新”(Pull to Refresh) 机制,让用户主动获取新动态,减少不必要的流量消耗。
8. 动态排名
最简单的动态排序方式是按照帖子创建时间排序,但如今的排名算法远不止于此,它们会确保“重要”的帖子排名更靠前。排名的核心思路是先选取能衡量帖子重要性的关键“信号”,然后找出合适的方法将这些信号结合起来计算最终的排名分数。
具体而言,我们可以选取与帖子重要性相关的特征,例如点赞数、评论数、分享次数、更新时间、是否包含图片/视频等,并基于这些特征计算评分。对于一个简单的排名系统来说,这通常已经足够。但更高级的排名系统会通过持续评估用户粘性、留存率、广告收入等指标,来不断优化自身的排序效果。
9. 数据分区
a. 文章及元数据分片
由于每天都会产生大量新帖子,并且读取负载极高,我们需要将数据分布到多个机器上,以实现高效的读写操作。对于存储帖子及其元数据的数据库,我们可以采用与Twitter 设计部分讨论的类似分片方案。
b. 动态数据分片
对于存储在内存中的动态数据,我们可以按照用户 ID 进行分区。我们可以尝试将某个用户的所有数据存储在同一台服务器上。在存储时,我们可以将用户 ID 传递给哈希函数,使其映射到特定的缓存服务器,并在该服务器上存储该用户的动态对象。此外,由于对于任何用户来说,我们通常不会存储超过 500 条动态 ID,因此不会出现单台服务器无法容纳该用户动态数据的情况。因此,获取某个用户的动态时,我们始终只需查询一台服务器。
为了支持未来的扩展和数据复制,我们必须使用一致性哈希(Consistent Hashing)。