设计 Twitter 搜索
Twitter 是最大的社交网络服务之一,用户可以在其中分享照片、新闻和基于文本的消息。本章将设计一个能够存储和搜索用户推文的服务。
类似问题
推文搜索。
难度级别
中等。
1. 什么是 Twitter 搜索?
Twitter 用户可以随时更新他们的状态。每条状态(称为推文)由纯文本组成,我们的目标是设计一个系统,能够对所有用户推文进行搜索。
2. 系统需求和目标
- 假设 Twitter 总共有 15 亿用户,其中 8 亿是每日活跃用户。
- Twitter 平均每天接收 4 亿条推文。
- 每条推文的平均大小为 300 字节。
- 假设每天有 5 亿次搜索。
- 搜索查询将包含由 AND/OR 组合的多个单词。
我们需要设计一个能够高效存储和查询推文的系统。
3. 容量估算和约束
存储容量:
- 每天新增推文数量:4 亿。
- 每条推文大小:300 字节。
- 每天总存储需求:
400M * 300 => 120GB/day- 每秒新增存储需求:
120GB / 24hours / 3600sec ~= 1.38MB/second4. 系统 API
我们可以通过 SOAP 或 REST API 来暴露服务功能,以下是搜索 API 的定义:
search(api_dev_key, search_terms, maximum_results_to_return, sort, page_token)参数:
- api_dev_key (string): 注册账户的开发者密钥。此密钥可用于根据分配的配额限制用户请求。
- search_terms (string): 包含搜索词的字符串。
- maximum_results_to_return (number): 返回的推文数量。
- sort (number): 可选排序模式:
- 按最新优先(0 - 默认)
- 按最佳匹配(1)
- 按最多点赞(2)
- page_token (string): 指定要返回结果集中哪一页的令牌。
返回值:
- JSON: 包含与搜索查询匹配的推文列表的信息。每个结果条目可包括以下字段:
- 用户 ID 和姓名
- 推文文本
- 推文 ID
- 创建时间
- 点赞数等。
5. 高级设计
从高层次来看,我们需要将所有状态存储在一个数据库中,并建立一个索引,用于记录每个单词出现在哪些推文中。这个索引将帮助我们快速找到用户尝试搜索的推文。

6. 详细组件设计
1. 存储: 我们需要每天存储120GB的新数据。考虑到这个巨大的数据量,我们需要设计一个数据分区方案,将数据高效地分配到多个服务器上。如果我们规划未来五年的存储需求,则需要以下存储空间:
120GB * 365days * 5years ~= 200TB如果我们希望任何时候存储容量不超过80%,则大约需要250TB的总存储空间。假设我们需要为所有推文保留一个额外副本以确保容错性,那么我们的总存储需求将达到500TB。如果我们假设一台现代服务器可以存储最多4TB的数据,那么我们将需要125台这样的服务器来存储未来五年的所有数据。
我们可以从一个简化的设计开始,将推文存储在MySQL数据库中。我们可以假设将推文存储在一个包含两个列的表中,分别是TweetID和TweetText。假设我们基于TweetID来进行数据分区。如果我们的TweetID在系统中是唯一的,我们可以定义一个哈希函数,将TweetID映射到一个存储服务器,以便将推文对象存储在那里。
如何创建系统范围内唯一的TweetID?如果我们每天接收到4亿条新推文,那么五年内我们能预期存储多少推文对象?
400M * 365 days * 5 years => 730 billion这意味着我们需要一个五字节的数字来唯一标识TweetID。假设我们有一个服务,可以在需要存储对象时生成唯一的TweetID(这里讨论的TweetID将类似于《设计Twitter》中讨论的TweetID)。我们可以将TweetID传递给哈希函数,以找到存储服务器,并将推文对象存储在那里。
2. 索引: 我们的索引应该是什么样子的?由于我们的推文查询将包含单词,我们需要构建一个索引,能够告诉我们每个单词出现在了哪个推文对象中。首先估算一下我们的索引会有多大。如果我们要为所有英语单词和一些著名的名词(如人名、城市名等)构建索引,假设我们有大约30万个英语单词和20万个名词,那么我们索引中的总单词数将为50万个。假设每个单词的平均长度为5个字符。如果我们将索引保存在内存中,我们将需要2.5MB的内存来存储所有单词:
500K * 5 => 2.5 MB假设我们只希望保留过去两年内的推文索引。由于我们将在5年内接收到7300亿条推文,那么在两年内我们将有2920亿条推文。考虑到每个TweetID为5字节,我们需要多少内存来存储所有TweetID? 2920亿 * 5 => 1460GB
所以我们的索引将类似于一个大型分布式哈希表,其中“key”将是单词,而“value”将是包含该单词的所有推文的TweetID列表。假设每条推文平均包含40个单词,且我们不会索引像“the”、“an”、“and”等介词和其他小单词,假设每条推文需要索引15个单词。这意味着每个TweetID将在我们的索引中存储15次。所以,我们需要的总内存来存储索引为:
(1460 * 15) + 2.5MB ~= 21 TB假设一台高端服务器具有144GB内存,我们将需要152台这样的服务器来存储我们的索引。
我们可以根据两个标准来对数据进行分片:
基于单词的分片: 在构建索引时,我们将遍历每条推文的所有单词,并计算每个单词的哈希值,以找到存储该单词的服务器。要查找包含特定单词的所有推文,我们只需要查询包含该单词的服务器。
这种方法存在几个问题:
- 如果某个单词变得热门怎么办?那么持有该单词的服务器将会有大量的查询请求,这种高负载会影响我们服务的性能。
- 随着时间的推移,一些单词可能会存储大量的TweetID,而其他单词的存储量较少,因此,在推文数量增长的过程中,保持单词的均匀分布是相当困难的。
为了解决这些问题,我们要么需要重新分区数据,要么使用一致性哈希。
基于推文对象的分片:在存储时,我们将把TweetID传递给哈希函数来找到相应的服务器,并在该服务器上索引推文中的所有单词。在查询特定单词时,我们必须查询所有服务器,每个服务器将返回一组TweetID。一个中央服务器将汇总这些结果,并返回给用户。
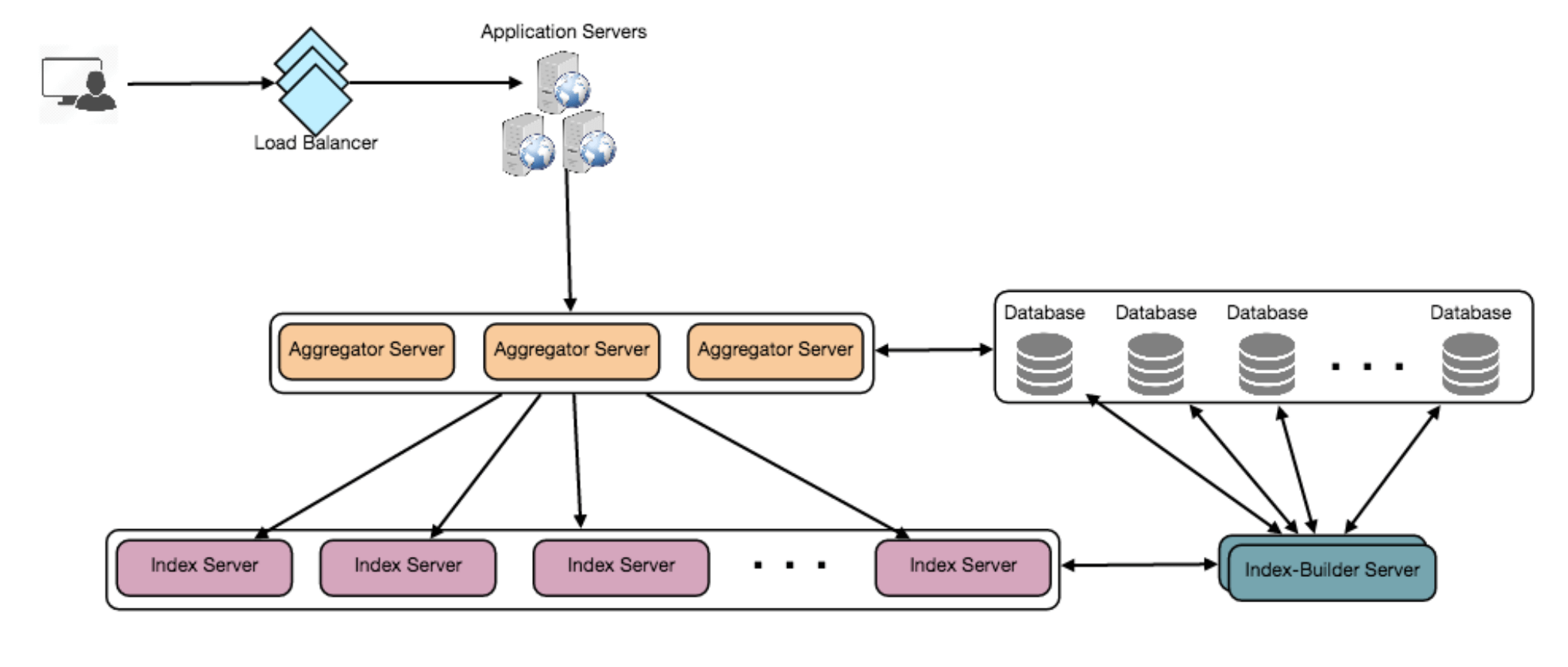
7. 容错
当一个索引服务器宕机时会发生什么?我们可以为每个服务器配置一个副本,如果主服务器宕机,副本可以在故障切换后接管。主服务器和副服务器将拥有相同的索引副本。
如果主服务器和副服务器同时宕机怎么办?我们必须分配一台新服务器,并在其上重新构建相同的索引。我们该怎么做呢?我们不知道哪些单词/推文存储在这台服务器上。如果我们使用的是“基于推文对象的分片”,那么最简单的解决方案就是遍历整个数据库,并使用哈希函数过滤TweetID,以找出所有存储在该服务器上的所需推文。这将是低效的,并且在服务器重建期间,我们将无法为用户提供查询服务,从而错过一些应该由用户看到的推文。
我们如何高效地获取推文与索引服务器之间的映射?我们必须构建一个反向索引,将所有TweetID映射到它们的索引服务器。我们的Index-Builder服务器可以保存这个信息。我们将需要构建一个哈希表,其中“key”是索引服务器编号,“value”是一个哈希集,包含所有存储在该索引服务器上的TweetID。请注意,我们将所有TweetID存储在一个哈希集中;这将使我们能够快速添加/删除索引中的推文。因此,现在每当一个索引服务器需要重建时,它只需向Index-Builder服务器请求所有需要存储的推文,然后获取这些推文来构建索引。这个方法肯定会很快。我们还应该为Index-Builder服务器配置一个副本以保证容错。
8. 缓存
为了应对热推文,我们可以在数据库前引入一个缓存。我们可以使用Memcached,将所有这种热推文存储在内存中。应用服务器在访问后端数据库之前,可以快速检查缓存中是否已有该推文。根据客户端的使用模式,我们可以调整需要多少缓存服务器。对于缓存驱逐策略,最少使用最近(LRU)策略似乎适合我们的系统。
9. 负载均衡
我们可以在系统的两个位置添加负载均衡层:1) 客户端和应用服务器之间,2) 应用服务器和后端服务器之间。最初,可以采用简单的轮询(Round Robin)方法,均匀地将传入的请求分配到后端服务器。这种负载均衡方法实现简单,并且不会引入额外开销。这个方法的另一个好处是,当服务器宕机时,负载均衡器会将其从轮询中移除,停止向其发送流量。轮询负载均衡的一个问题是,它不会考虑服务器负载。如果一台服务器超载或运行缓慢,负载均衡器仍会将新的请求发送到该服务器。为了解决这个问题,可以部署一个更智能的负载均衡解决方案,定期查询后端服务器的负载情况,并根据负载情况调整流量。
10. 排名
如果我们想根据社交图距离、流行度、相关性等排名搜索结果,该怎么做呢?
假设我们想根据推文的流行度进行排名,比如推文获得了多少赞或评论等。在这种情况下,我们的排名算法可以计算一个“流行度数字”(基于点赞数等),并将其与索引一起存储。每个分区可以在返回结果之前,基于流行度数字对结果进行排序。聚合服务器将汇总所有这些结果,按照流行度数字进行排序,然后将排名靠前的结果发送给用户。